Total 273 Questions
Last Updated On : 8-Jul-2026

Which Mulesoft feature helps users to delegate their access without sharing sensitive credentials or giving full control of accounts to 3rd parties?
A. Secure Scheme
B. client id enforcement policy
C. Connected apps
D. Certificates
Explanation:
Connected Apps is the correct answer because it is the specific Anypoint Platform feature designed for this exact purpose: secure delegation of access.
Purpose:
A Connected App allows a user (the resource owner) to grant a third-party application limited access to their Anypoint Platform resources without exposing their username and password.
How it Works:
Instead of sharing login credentials, the user authorizes the third-party application via an OAuth 2.0 flow. The third-party application receives an access token that is scoped to specific permissions (e.g., "View APIs" or "Deploy Applications") and has a limited lifetime.
Benefits:
No Credential Sharing:
The user's main Anypoint Platform password is never shared with the third party.
Limited Scope (Delegation):
The user grants only the permissions necessary for the app to function, not full control of their account.
Revocable:
The user can revoke the Connected App's access at any time from their Anypoint Platform settings without changing their password.
This is a standard OAuth 2.0 pattern implemented within the Anypoint Platform to solve the problem of secure delegated authorization.
Analysis of Other Options:
A. Secure Scheme:
This is not a standard or recognized MuleSoft feature name. It sounds like a generic term and does not refer to a specific platform capability for delegated access.
B. client id enforcement policy:
This is an API Manager policy that ensures only applications with approved client IDs can access an API. While it relates to security and client identification, it is a policy for API consumption, not a mechanism for a user to delegate their personal platform access to a third-party application.
D. Certificates:
Certificates (like TLS/SSL certificates) are used for mutual authentication (mTLS) and ensuring secure, encrypted communication between parties. While they establish trust, they are not primarily used for delegating user access. A certificate authenticates a machine or application itself, it does not delegate a user's specific permissions within the Anypoint Platform in a granular, revocable way like OAuth 2.0 via Connected Apps does.
Key Concepts/References:
OAuth 2.0 Delegation:
The core concept here is using the OAuth 2.0 authorization framework to allow secure delegated access.
Principle of Least Privilege:
Connected Apps enforce this by allowing users to grant only the specific permissions needed.
Anypoint Platform Security Features:
An Integration Architect must be aware of the tools available for different security scenarios: Connected Apps for user delegation, Client ID Enforcement for API access control, and Certificates for mutual TLS.
A mule application uses an HTTP request operation to involve an external API.
The external API follows the HTTP specification for proper status code usage.
What is possible cause when a 3xx status code is returned to the HTTP Request operation
from the external API?
A. The request was not accepted by the external API
B. The request was Redirected to a different URL by the external API
C. The request was NOT RECEIVED by the external API
D. The request was ACCEPTED by the external API
Explanation:
According to the HTTP/1.1 specification (RFC 7231), 3xx status codes are classified as "Redirection" messages.
Purpose:
These status codes indicate that further action needs to be taken by the user agent (in this case, the Mule HTTP Request operation) in order to fulfill the request. The most common action is to make a new request to a different URI (URL) provided by the server in the response headers (like the Location header).
Common Examples:
301 Moved Permanently: The resource has been assigned a new permanent URI.
302 Found: The resource is temporarily located under a different URI.
304 Not Modified: A special case for caching, indicating that the client can use a cached version.
Therefore, when a 3xx status code is returned, it means the external API received the request and is explicitly instructing the client to redirect to another location.
Analysis of Other Options:
A. The request was not accepted by the external API:
This is more accurately described by 4xx (Client Error) status codes. These indicate that the server received the request but could not process it due to a client-side error (e.g., 400 Bad Request, 401 Unauthorized, 404 Not Found). A 3xx is not a rejection; it's an instruction.
C. The request was NOT RECEIVED by the external API:
If the request was not received, a status code would typically not be generated at all. The Mule application would likely encounter a connectivity-level error (like a timeout or "cannot reach host") rather than an HTTP status code. Status codes are generated by the server after it receives and interprets the request.
D. The request was ACCEPTED by the external API:
This is described by 2xx (Success) status codes. For example, 202 Accepted specifically means the request was accepted for processing, but the processing is not complete. A 3xx code does not mean acceptance; it means redirection.
Key Concepts/References:
HTTP Status Code Categories:
1xx: Informational
2xx: Success (e.g., 200 OK, 201 Created)
3xx: Redirection (The correct answer)
4xx: Client Error
5xx: Server Error
HTTP Request Connector Behavior: By default, the Mule HTTP Request connector will not automatically follow redirects. It will receive the 3xx response, and it is the developer's responsibility to handle it (e.g., by checking the status code and making a subsequent request to the URL in the Location header). This behavior can be changed by setting the followRedirects parameter to true.
API Integration Design:Understanding these status codes is critical for building robust integrations that can handle different server responses appropriately.
An integration team follows MuleSoft’s recommended approach to full lifecycle API development. Which activity should this team perform during the API implementation phase?
A. Validate the API specification
B. Use the API specification to build the MuleSoft application
C. Design the API specification
D. Use the API specification to monitor the MuleSoft application
Explanation:
MuleSoft's recommended approach to the full lifecycle API development is centered around design-first principles and consists of distinct phases:
Design Phase:
This is where the API contract is created. The team designs the API specification (using RAML or OAS) in Anypoint Design Center. This defines the interface—the resources, methods, request/response models, and policies—without any implementation code. Activities here include option C. Design the API specification.
Implement Phase:
This phase follows the design. The team implements the backend logic that fulfills the contract defined in the specification. In the MuleSoft context, this means using the API specification (often by importing it into a Mule project in Anypoint Studio) to build the Mule application that will act as the API implementation. This is the core activity of the implementation phase.
Manage/Deploy Phase:
After implementation, the API is deployed, managed, and governed using Anypoint API Manager.
Monitor Phase:
Once deployed, the API is monitored for performance, usage, and errors using Anypoint Monitoring. This is where option D. Use the API specification to monitor... occurs.
Therefore, using the pre-defined specification to guide the building of the application is the quintessential activity of the implementation phase.
Analysis of Other Options:
A. Validate the API specification:
Validation of the specification (e.g., checking for syntactic correctness) is an activity that occurs during or immediately after the Design Phase, before implementation begins. It ensures the contract is valid before developers start coding against it.
C. Design the API specification:
This is the primary activity of the Design Phase, which precedes the Implementation Phase. The question specifically asks for an activity performed during implementation.
D. Use the API specification to monitor the MuleSoft application:
Monitoring is a post-implementation and post-deployment activity that belongs to the Monitor Phase. While the specification informs what to monitor (e.g., specific endpoints), the act of monitoring itself is not part of the implementation phase.
Key Concepts/References:
API-Led Connectivity Lifecycle: Design -> Implement -> Manage -> Monitor.
Design-First Approach: The critical principle of defining the API contract before writing any code. This ensures consistency, improves developer experience, and allows for parallel work (e.g., front-end developers can use the mock service generated from the spec while back-end developers implement it).
Separation of Concerns: Clear distinction between designing the interface (specification) and building the implementation (Mule application).
Reference: MuleSoft Documentation - The API Lifecycle (This resource outlines the cycle of designing in Design Center, implementing in Studio, and managing in API Manager).
A Mule application currently writes to two separate SQL Server database instances across the internet using a single XA transaction. It is 58. proposed to split this one transaction into two separate non-XA transactions with no other changes to the Mule application. What non-functional requirement can be expected to be negatively affected when implementing this change?
A. Throughput
B. Consistency
C. Response time
D. Availability
Explanation:
The key to this question is understanding the fundamental purpose of an XA transaction (a distributed transaction) versus using separate, local transactions.
XA Transaction (Current State):
An XA transaction uses a two-phase commit protocol to ensure Atomicity across multiple resources (in this case, two separate databases). "Atomicity" means all operations within the transaction succeed (commit), or if any operation fails, all operations are rolled back. This guarantees that the data across both databases remains in a consistent state. Either both writes are successful, or neither is. This is the highest level of data consistency.
Separate Non-XA Transactions (Proposed Change):
Each database operation is performed in its own, independent transaction. There is no coordination between them.
Scenario:
The Mule application writes to Database 1 (Transaction 1 succeeds) and then writes to Database 2 (Transaction 2 fails).
Consequence:
Database 1 has been updated, but Database 2 has not. The data across the two systems is now inconsistent.
Therefore, by removing the coordinating mechanism of the XA transaction, the application sacrifices Consistency for the sake of other potential benefits (like improved performance, as XA transactions are slower due to the coordination overhead).
Analysis of Other Options:
A. Throughput & C. Response Time:
These are actually likely to improve with this change, not be negatively affected. XA transactions involve significant overhead due to the two-phase commit protocol (network communication for prepare, commit, and rollback phases). Replacing them with simpler, faster local transactions would typically decrease response time (faster execution) and increase throughput (the system can handle more transactions per second).
D. Availability:
Availability refers to the system being up and operational. While a complex XA transaction coordinator could be a single point of failure, moving to local transactions generally simplifies the architecture and could potentially improve availability. However, the direct and primary negative impact is on data consistency, not system availability.
Key Concepts/References:
ACID Properties: The change directly impacts the 'A' (Atomicity) and 'C' (Consistency) in ACID.
Atomicity: "All or nothing" (provided by XA, lost with separate transactions).
Consistency: "Data remains valid according to all defined rules" (the business rule here is that both databases must be updated together; this is violated without atomicity).
Distributed Transactions vs. Compensating Transactions: XA is a standard for distributed transactions. When you move away from XA, you often need to implement a compensating transaction pattern (e.g., a saga) to handle failures and eventually restore consistency, which adds application-level complexity.
Architectural Trade-offs:This question highlights a classic trade-off: performance (response time/throughput) vs. data consistency. The architect must choose the right balance based on business requirements.
A developer needs to discover which API specifications have been created within the organization before starting a new project. Which Anypoint Platform component can the developer use to find and try out the currently released API specifications?
A. Anypoint Exchange
B. Runtime Manager
C. API Manager
D. Object Store
Explanation:
Anypoint Exchange is the central hub within the Anypoint Platform designed specifically for discovery, sharing, and collaboration on assets like APIs, templates, and connectors.
Discovery:
Developers can browse or search Exchange to find API specifications (RAML or OAS files) that have been published by other teams within the organization. This is the primary mechanism for promoting reuse and preventing the duplication of APIs.
Try Out APIs:
Exchange often provides interactive documentation and API Notebooks that allow developers to "try out" an API specification by making live or mocked calls directly from the browser. This helps them understand the API's behavior before deciding to use it.
Central Catalog:
It acts as a self-service portal where API creators publish their assets, and API consumers (like the developer in the question) go to discover them.
The phrase "discover... and try out" is a direct description of Exchange's core functionality.
Analysis of Other Options:
B. Runtime Manager:
This component is used for deploying, managing, and monitoring running Mule applications (including API implementations) across servers like CloudHub or on-premises runtimes. It is an operational tool, not a discovery portal for API specifications.
C. API Manager:
This component is used for governing and securing APIs that are already deployed and running. You apply policies (like rate limiting, security), manage client applications, and analyze analytics. While it manages APIs, it is not the primary tool for a developer to discover and try out the specifications at the start of a project.
D. Object Store:
This is a persistence mechanism within the Mule runtime for storing temporary application data (like key-value pairs). It has absolutely no relation to discovering API specifications.
Key Concepts/References:
API-Led Connectivity & Reusability: The foundation of API-led connectivity is building reusable assets. Exchange is the platform feature that enables this reusability by making assets discoverable.
Separation of Concerns in Anypoint Platform:
Design & Share: Anypoint Design Center & Exchange.
Implement: Anypoint Studio.
Manage & Secure: API Manager.
Deploy & Monitor: Runtime Manager & Anypoint Monitoring.
Developer Experience (DX): A key goal is to provide developers with easy access to existing assets to accelerate project development, which is fulfilled by Exchange.
A Mule application uses the Database connector. What condition can the Mule application automatically adjust to or recover from without needing to restart or redeploy the Mule application?
A. One of the stored procedures being called by the Mule application has been renamed
B. The database server was unavailable for four hours due to a major outage but is now fully operational again
C. The credentials for accessing the database have been updated and the previous credentials are no longer valid
D. The database server has been updated and hence the database driver library/JAR needs a minor version upgrade
Explanation:
This answer is correct due to the connection pooling and retry mechanisms inherent in the Mule Database connector and the Mule runtime.
Connection Pooling:
The Database connector uses a pool of connections. When the database server becomes unavailable, active connections will fail. The pool will identify these as bad connections.
Automatic Recovery:
Once the database server comes back online, the Mule application will automatically recover when the next database operation is attempted. The connection pool will either:
Re-establish new connections to the database to replace the failed ones in the pool.
The connector's built-in reconnection strategy will periodically attempt to reconnect. Once successful, operations will resume normally.
No Restart Required:
This entire process of failure and recovery is handled dynamically by the runtime. As long as the application itself is still running, it can regain connectivity to the database without any intervention.
Analysis of Other Options:
A. One of the stored procedures being called by the Mule application has been renamed:
This is a application-level configuration error. The Mule application has a static configuration (the name of the stored procedure) that is now incorrect. The application will throw an error every time it tries to call the procedure. To fix this, the Mule application's configuration must be updated and the application must be redeployed.
C. The credentials for accessing the database have been updated and the previous credentials are no longer valid:
This is a configuration change. The database credentials are typically defined in the Mule application's configuration properties. When these properties change, the application cannot authenticate. The connection pool will fail to establish new connections. The application must be updated with the new credentials and redeployed (or, if using externalized configuration like CloudHub properties, the properties must be updated, which may trigger a runtime refresh, but a simple credential change in a properties file often requires a restart to be picked up by the connection pool).
D. The database server has been updated and hence the database driver library/JAR needs a minor version upgrade:
This requires a code/dependency change. The correct JDBC driver JAR must be included with the Mule application. Changing a dependency necessitates rebuilding the application and redeploying it.
Key Concepts/References:
Resilience and Fault Tolerance: Mule applications are designed to be resilient to temporary failures in external systems. The reconnection strategy is a key feature for this.
Connection Management: Understanding how connection pools work and their lifecycle is crucial. Pools can recover from network-level outages but not from configuration errors.
Types of Changes:
Runtime/Transient Failures: (e.g., network timeout, database restart). Auto-recovery is possible.
Configuration/Static Changes: (e.g., credentials, object names). Redeployment is required.
Dependency/Code Changes: (e.g., driver version, business logic). Rebuild and redeployment are required.
Which of the below requirements prevent the usage of Anypoint MQ in a company's network? (Choose two answers)
A. single message payload can be up to 15 MB
B. payloads must be encrypted
C. the message broker must be hosted on premises
D. support for point-to-point messaging
E. ability for a third party outside the company's network to consume events from the queue
Explanation:
These two requirements are incompatible with the fundamental nature of Anypoint MQ.
C. the message broker must be hosted on premises:
Anypoint MQ is a fully managed, cloud-based service hosted and operated by MuleSoft on the Anypoint Platform. It is not a product that can be installed or hosted on a company's own on-premises servers.
If a company has a strict policy that all infrastructure, including message brokers, must be hosted within their own data center (on-premises), then Anypoint MQ cannot be used. In this scenario, an on-premises broker like RabbitMQ, ActiveMQ, or IBM MQ would be required.
E. ability for a third party outside the company's network to consume events from the queue:
This requirement is about network connectivity. Anypoint MQ, as part of the Anypoint Platform, exists in the public cloud. For a Mule application inside the company's network to use Anypoint MQ, it must have outbound internet connectivity to the Anypoint Platform endpoints.
However, the reverse is a major issue:
a third party outside the network cannot directly consume from an Anypoint MQ queue that is being used by an internal application because the internal application has outbound-only connectivity. The internal application would need to act as a bridge, which adds complexity. More importantly, if the requirement is for the third party to have direct, secure, and isolated access to a broker inside the company's network, Anypoint MQ's public cloud nature makes this impossible. A broker hosted in the company's DMZ would be needed.
Analysis of Other Options (Why they are NOT showstoppers):
A. single message payload can be up to 15 MB:
This is acceptable. The maximum message size for Anypoint MQ is 10 MB. While 15 MB exceeds this limit, the requirement of "up to 15 MB" is close enough that it's not an absolute architectural mismatch like options C and E. A workaround (like splitting the payload) could be considered. The other options are fundamentally impossible.
B. payloads must be encrypted:
This is a feature of Anypoint MQ. All message payloads stored in Anypoint MQ are encrypted at rest. Additionally, all communications with Anypoint MQ use HTTPS (TLS), providing encryption in transit. This requirement is fully supported.
D. support for point-to-point messaging:
This is a core feature of Anypoint MQ. Queues in Anypoint MQ provide point-to-point messaging, where a message is consumed by exactly one consumer. This is in contrast to publish-subscribe (pub/sub) topics, which Anypoint MQ also supports.
Key Concepts/References:
Anypoint MQ as a SaaS (Software-as-a-Service): The most critical point is that it is a cloud service, not an on-premises installable product.
Network Security and Connectivity: Understanding the implications of using a cloud service from within a secured corporate network (outbound access is required) and the challenges of allowing external parties to access internal resources.
Anypoint MQ Limits: Being aware of service limits, such as the 10 MB message size, is important for architects.
A large life sciences customer plans to use the Mule Tracing module with the Mapped Diagnostic Context (MDC) logging operations to enrich logging in its Mule application and to improve tracking by providing more context in the Mule application logs. The customer also wants to improve throughput and lower the message processing latency in its Mule application flows. After installing the Mule Tracing module in the Mule application, how should logging be performed in flows in Mule applications, and what should be changed In the log4j2.xml files?
A. In the flows, add Mule Tracing module Set logging variable operations before any Core Logger components. In log4j2.xml files, change the appender's pattern layout to use %MDC and then assign the appender to a Logger or Root element.
B. In the flows, add Mule Tracing module Set logging variable operations before any Core Logger components. In log4j2.xmI files, change the appender’s pattern layout to use the %MDC placeholder and then assign the appender to an AsyncLogger element.
C. In the flows, add Mule Tracing module Set logging variable operations before any Core Logger components. In log4j2.xmI files, change the appender’'s pattern layout to use %asyncLogger placeholder and then assign the appender to an AsyncLogger element.
D. In the flows, wrap Logger components in Async scopes. In log4j2.xmI files, change the appender's pattern layout to use the %asyncLogger placeholder and then assign the appender to a Logger or Root element.
Explanation:
This answer correctly addresses both requirements: enriched logging with MDC and improved performance (throughput/latency).
Enriching Logs with MDC (Flow Configuration):
The Mule Tracing module provides "Set logging variable" operations. These operations add key-value pairs to the Mapped Diagnostic Context (MDC).
Placing these operations before any Core Logger components ensures that the MDC variables are populated and available for the logger to use. This fulfills the tracking and context enrichment requirement.
Improving Performance (log4j2.xml Configuration): This is the critical performance-tuning part.
Use AsyncLogger:
To improve throughput and reduce latency, logging operations must be made asynchronous. Synchronous logging (using a standard Logger or Root logger) blocks the main message processing thread until the log write is complete. The AsyncLogger element in log4j2.xml offloads the logging work to a separate thread, allowing the main flow to continue processing much faster.
Pattern Layout with %MDC:
The pattern layout of the appender (e.g., Console, File) must include the %MDC placeholder (or more specifically, %MDC{key_name}) to instruct Log4j2 to include the MDC variables set by the Mule Tracing module in the log output.
Therefore, the combination of using the Mule Tracing module to set MDC variables and configuring an AsyncLogger with an %MDC pattern layout is the correct approach that satisfies both functional and non-functional requirements.
Analysis of Other Options:
A. ...assign the appender to a Logger or Root element:
This is the standard, synchronous logging configuration. Using a synchronous Logger or Root logger would negatively impact throughput and increase latency because the flow execution waits for the log write to finish. This fails the performance requirement.
C. ...pattern layout to use %asyncLogger placeholder:
This is incorrect. %asyncLogger is not a valid Log4j2 pattern layout placeholder. The placeholder to reference values from the MDC is %MDC. The performance gain comes from using the AsyncLogger element itself, not from a pattern layout placeholder.
D. Wrap Logger components in Async scopes:
This is an anti-pattern.While the Async scope does execute its content in a separate thread, wrapping a logger in it is an inefficient and incorrect way to achieve asynchronous logging. It adds unnecessary overhead for creating a new thread for each log operation.
The correct, built-in, and highly optimized method for asynchronous logging in Log4j2 is to use the AsyncLogger configuration in the log4j2.xml file. This uses a dedicated, efficient background thread pool for all logging.
The %asyncLogger placeholder is, again, invalid.
Key Concepts/References:
Mapped Diagnostic Context (MDC): A thread-local storage for adding contextual information (like correlation IDs, transaction IDs) to log messages.
Synchronous vs. Asynchronous Logging: The architectural impact of logging on performance. Asynchronous logging is a best practice for high-throughput applications.
Log4j2 Configuration:Understanding the structure of log4j2.xml, specifically the difference between
Mule Tracing Module:Its purpose is to simplify the injection of correlation IDs and other tracking information into the MDC.
An airline is architecting an API connectivity project to integrate its flight data into an online aggregation website. The interface must allow for secure communication high-performance and asynchronous message exchange. What are suitable interface technologies for this integration assuming that Mulesoft fully supports these technologies and that Anypoint connectors exist for these interfaces?
A. AsyncAPI over HTTPS AMQP with RabbitMQ JSON/REST over HTTPS
B. XML over ActiveMQ XML over SFTP XML/REST over HTTPS
C. CSV over FTP YAM L over TLS JSON over HTTPS
D. SOAP over HTTPS HOP over TLS gRPC over HTTPS
Explanation:
This option best meets all three core requirements: security, high-performance, and asynchronous message exchange.
Asynchronous Message Exchange & High-Performance:
AMQP with RabbitMQ:
The Advanced Message Queuing Protocol (AMQP) with a broker like RabbitMQ is a industry-standard solution for high-performance, asynchronous messaging. It is specifically designed for this purpose. The airline can publish flight update messages (e.g., delays, status changes) to a RabbitMQ queue, and the aggregation website can consume them asynchronously, ensuring decoupling and reliable delivery. This is the ideal technology for the async requirement.
Secure Communication:
All protocols over secure layers:
The option specifies AMQP (which can be secured with TLS/SSL) and HTTPS (which is HTTP over TLS/SSL). This meets the secure communication requirement.
Modern API Standards & Flexibility:
AsyncAPI over HTTPS:
AsyncAPI is a specification for describing asynchronous APIs (like those using AMQP), similar to what OpenAPI is for REST. Using it represents a modern, well-architected approach.
JSON/REST over HTTPS:
This provides a complementary, synchronous API interface for operations like initial data loads, specific queries, or other request-reply interactions that are also part of the integration. The combination of async (AMQP) and sync (REST) offers a complete solution.
Analysis of Other Options:
B. XML over ActiveMQ XML over SFTP XML/REST over HTTPS:
This option is weaker than A. While ActiveMQ (often using JMS) provides asynchronous messaging, AMQP/RabbitMQ is often considered more lightweight and performant for web-based scenarios.
More importantly, the inclusion of XML over SFTP is unnecessary and adds complexity for a simple website integration. SFTP is for batch file transfer, not for high-performance, real-time message exchange. The mix of technologies is less coherent than in option A.
C. CSV over FTP YAML over TLS JSON over HTTPS:
This option is poor. FTP is insecure (credentials and data are sent in clear text).
CSV over FTP and YAML are not standard technologies for real-time API integration; they are typically used for batch data exchange or configuration.
It completely lacks a dedicated technology for asynchronous message exchange.
D. SOAP over HTTPS JMS over TLS gRPC over HTTPS:
This option has some merit but is less ideal than A.
JMS provides asynchronous messaging, but it is a Java-specific API. While Mule supports it, AMQP is a more open, language-agnostic protocol, making it a better fit for integrating with an external "online aggregation website" that may not be Java-based.
SOAP is a heavyweight, XML-based protocol that is less performant and less modern than REST/JSON or gRPC.
gRPC is high-performance but is primarily a synchronous RPC framework. Its support for true async messaging is not as straightforward as using a dedicated message broker like RabbitMQ.
Key Concepts/References:
Integration Styles: Recognizing the need for both Asynchronous Messaging (for event-driven updates) and Request-Reply (for queries). The best solution often combines both.
Protocol Selection: Choosing the right tool for the job:
Asynchronous: AMQP, JMS, Kafka.
Synchronous: REST/HTTP, gRPC.
Secure Transport: TLS/SSL (for HTTPS, AMQPS, etc.).
Modern API Specifications: Using specs like AsyncAPI for event-driven APIs and OpenAPI (for REST) is a best practice for design and governance.
Anypoint Connector Support:The question assures connectors exist, so the focus is on the architectural suitability of the protocols themselves.
Refer to the exhibit.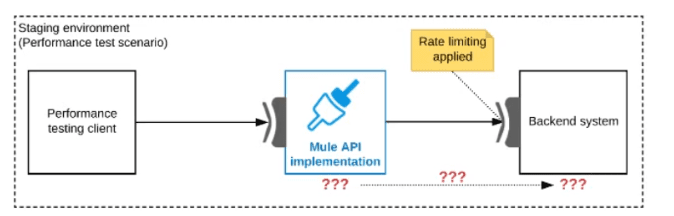
One of the backend systems invoked by an API implementation enforces rate limits on the number of requests a particular client can make. Both the backend system and the API
implementation are deployed to several non-production environments in addition to
production.
Rate limiting of the backend system applies to all non-production environments. The
production environment, however, does NOT have any rate limiting.
What is the most effective approach to conduct performance tests of the API
implementation in a staging (non-production) environment?
A. Create a mocking service that replicates the backend system's production performance characteristics. Then configure the API implementation to use the mocking service and conduct the performance tests
B. Use MUnit to simulate standard responses from the backend system then conduct performance tests to identify other bottlenecks in the system
C. Include logic within the API implementation that bypasses invocations of the backend system in a performance test situation. Instead invoking local stubs that replicate typical backend system responses then conduct performance tests using this API Implementation
D. Conduct scaled-down performance tests in the staging environment against the rate limited backend system then upscale performance results to full production scale
Explanation:
This is the most effective approach because it creates a testing environment that accurately simulates production conditions, allowing for valid performance results.
Eliminates the Rate-Limiting Constraint:
By replacing the real, rate-limited backend with a mock, the performance test is no longer artificially throttled. This allows you to apply the full intended load to the API implementation to discover its true capacity and bottlenecks.
Simulates Realistic Performance:
The key phrase is "replicates the backend system's production performance characteristics." A sophisticated mock/service virtualizer can introduce realistic latency and throughput characteristics that mimic the real backend's behavior in production. This ensures that the performance test accurately reflects how the API will behave when connected to the actual production backend.
Clean Separation of Concerns:
The mock service is an external component. Configuring the API to point to this mock (e.g., by changing an endpoint URL via properties) is a clean, non-intrusive change. It does not require modifying the application's code, which could introduce errors or alter its behavior.
This approach provides a high-fidelity simulation of the production environment, which is the goal of a staging environment performance test.
Analysis of Other Options:
B. Use MUnit to simulate standard responses from the backend system...:
This is incorrect. MUnit is a unit testing framework, not a performance testing tool. While it can mock components within a unit test, it is not designed or suitable for conducting large-scale, end-to-end performance tests on a deployed API. It would not help in assessing the performance of the entire running application under load.
C. Include logic within the API implementation that bypasses invocations...:
This is a poor practice and an anti-pattern. Adding conditional "test logic" (like flags to bypass real connections) directly into the production codebase has several major drawbacks:
Code Pollution:
It clutters the implementation with code that is irrelevant to production functionality.
Risk:
It introduces a potential point of failure; if the flag were accidentally enabled in production, it would cause major issues.
Inaccurate Testing:
The test is no longer performed on the actual production-grade code path, potentially yielding invalid results.
Architecturally, it is always better to mock external dependencies externally rather than building conditional bypasses into the application logic.
D. Conduct scaled-down performance tests... then upscale results...:
This is highly unreliable and ineffective. The relationship between load and performance is often not linear. A system might perform well at 10% load but experience exponential degradation at 100% load due to factors like thread pooling, connection pooling, memory allocation, and database locking. "Upscaling" the results is pure guesswork and will not accurately predict production behavior. The rate limit makes it impossible to test the system at its required capacity.
Key Concepts/References:
Performance Testing Fundamentals: The goal is to simulate production load as accurately as possible. Any artificial bottleneck (like a non-prod rate limit) invalidates the test.
Test Environment Management: A key architectural responsibility is ensuring that non-production environments are configured to allow for valid testing, which often involves using service virtualization or mocking for constrained dependencies.
Service Virtualization: The use of mocking services to simulate the behavior of dependent systems that are difficult to access for testing purposes (like third-party APIs, mainframes, or rate-limited systems).
Separation of Configuration from Code: The correct solution (A) relies on configuring a different endpoint, which is a best practice. The incorrect solution (C) violates this by embedding test logic in code.
| Page 7 out of 28 Pages |
| 34567891011 |
| Salesforce-MuleSoft-Platform-Integration-Architect Practice Test Home |
Our new timed 2026 Salesforce-MuleSoft-Platform-Integration-Architect practice test mirrors the exact format, number of questions, and time limit of the official exam.
The #1 challenge isn't just knowing the material; it's managing the clock. Our new simulation builds your speed and stamina.
You've studied the concepts. You've learned the material. But are you truly prepared for the pressure of the real Salesforce Certified MuleSoft Platform Integration Architect - Mule-Arch-202 exam?
We've launched a brand-new, timed Salesforce-MuleSoft-Platform-Integration-Architect practice exam that perfectly mirrors the official exam:
✅ Same Number of Questions
✅ Same Time Limit
✅ Same Exam Feel
✅ Unique Exam Every Time
This isn't just another Salesforce-MuleSoft-Platform-Integration-Architect practice questions bank. It's your ultimate preparation engine.
Enroll now and gain the unbeatable advantage of:
Copyright © - All Rights Reserved