Total 257 Questions
Last Updated On : 8-Jul-2026

Universal Containers has received complaints that customers are being called by multiple Sales Reps where the second Sales Rep that calls is unaware of the previous call by their coworker. What is a data quality problem that could cause this?
A. Missing phone number on the Contact record.
B. Customer phone number has changed on the Contact record.
C. Duplicate Contact records exist in the system.
D. Duplicate Activity records on a Contact.
Explanation:
Correct Answer: C. Duplicate Contact records exist in the system
Duplicate Contact records are a common data quality issue in CRM systems. If the same customer exists more than once, Sales Reps may log calls or activities against different records, unaware they are speaking to the same person. This creates a fragmented customer history and leads to poor customer experience, as multiple reps call the same person without visibility into prior interactions. Managing duplicates through matching rules, duplicate rules, and possibly an MDM strategy is critical.
Why not the others?
A. Missing phone number on the Contact record:
A missing phone number would prevent a call from being made at all, not cause duplicate calls. While it’s a data quality issue, it does not explain why multiple reps would contact the same customer unknowingly.
B. Customer phone number has changed on the Contact record:
If a customer’s phone number changes, the risk is inability to reach them or contacting the wrong number, not multiple reps calling the same person. This is an accuracy issue, but it doesn’t fit the scenario of duplicate outreach.
D. Duplicate Activity records on a Contact:
Duplicate activities might clutter reporting but would still be tied to the same Contact record. Reps would see that another call has already been logged if they’re viewing the same record, so this wouldn’t cause unawareness of previous calls.
Reference:
Salesforce Help: Manage Duplicates
Salesforce Architect Guide: Master Data Management
DreamHouse Realty has a data model as shown in the image. The Project object has a private sharing model, and it has Roll-Up summary fields to calculate the number of resources assigned to the project, total hours for the project, and the number of work items associated to the project. There will be a large amount of time entry records to be loaded regularly from an external system into Salesforce.
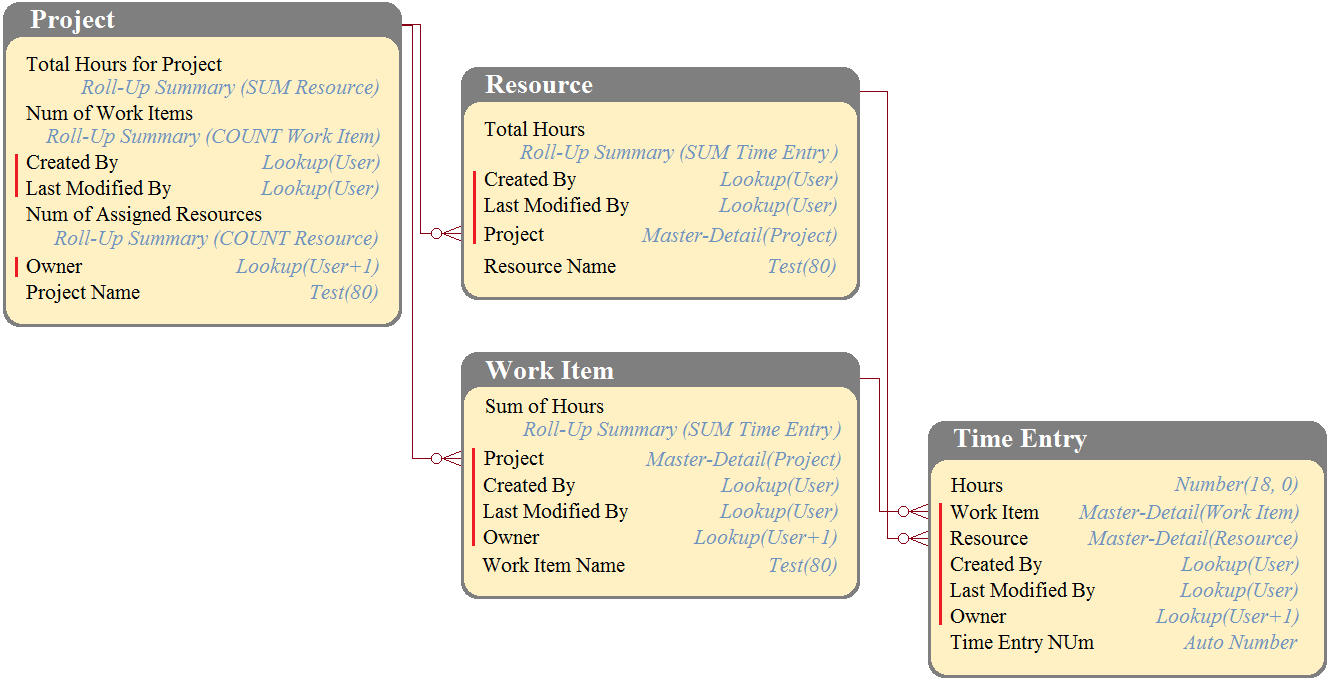
What should the Architect consider in this situation?
A. Load all data after deferring sharing calculations.
B. Calculate summary values instead of Roll-Up by using workflow.
C. Calculate summary values instead of Roll-Up by using triggers.
D. Load all data using external IDs to link to parent records.
Explanation:
✅ Correct Answer: A. Load all data after deferring sharing calculations
When loading large volumes of child records (like Time Entries) into Salesforce, performance can be severely impacted if sharing rules and recalculations are triggered during each insert/update. Since Project uses a private sharing model, every new Time Entry affects access recalculations and roll-up summaries. By using the “defer sharing calculations” option, the Architect ensures data can be loaded efficiently without constant recalculation. Once the load finishes, sharing rules can be recalculated in bulk, improving performance and stability.
Why not the others?
❌ B. Workflow for summaries:
Workflows cannot calculate aggregate values across related child records. They only update fields on the same record. Roll-Up Summaries are the native way to handle aggregation. Attempting to use workflows here is not feasible, as workflows lack the ability to roll up large datasets.
❌ C. Triggers for summaries:
Triggers could theoretically calculate roll-up values, but this adds unnecessary customization and performance risk. With millions of Time Entries, trigger logic would slow down processing, risk hitting governor limits, and duplicate functionality already provided by Salesforce’s Roll-Up Summary fields. It also creates long-term maintenance complexity.
❌ D. Load data using external IDs:
External IDs are useful for linking child records to parent objects during a data load. However, they do not address the performance issue caused by roll-up calculations and sharing recalculations. This option may help establish relationships, but it does not solve the core problem described in the scenario.
Reference:
Salesforce Help: Defer Sharing Calculations
Salesforce Best Practices for Large Data Volumes
Universal Containers (UC) has built a custom application on Salesforce to help track shipments around the world. A majority of the shipping records are stored on premise in an external data source. UC needs shipment details to be exposed to the custom application, and the data needs to be accessible in real time. The external data source is not OData enabled, and UC does not own a middleware tool. Which Salesforce Connect procedure should a data architect use to ensure UC's requirements are met?
A. Write an Apex class that makes a REST callout to the external API.
B. Develop a process that calls an inviable web service method.
C. Migrate the data to Heroku and register Postgres as a data source.
D. Write a custom adapter with the Apex Connector Framework.
Explanation:
Salesforce Connect lets Salesforce integrate external systems in real time without duplicating data. By default, it relies on OData-enabled sources, but when a source isn’t OData-enabled, architects can use the Apex Connector Framework to build a custom adapter. This adapter defines how Salesforce queries and displays data from the external system. It ensures shipment details are always up to date, accessible in Salesforce as external objects, and doesn’t require middleware.
🚫 Why not the others?
A. REST callout with Apex:
A callout only retrieves data on demand but doesn’t provide the seamless external object experience that Salesforce Connect gives. Reps wouldn’t see data in list views, reports, or related lists without custom UI.
B. Invocable web service method:
Invocable methods are meant for process automation. They can’t expose external data in real time as Salesforce records, so they don’t solve UC’s reporting and integration needs.
C. Heroku Postgres as source:
Migrating to Heroku adds cost and complexity. UC needs direct integration with the on-prem system, not another data store in the middle.
📚 Reference:
Salesforce Developer Guide: Apex Connector Framework
Salesforce Help: Salesforce Connect Overview
Universal Container (UC) has accumulated data over years and has never deleted data from its Salesforce org. UC is now exceeding the storage allocations in the org. UC is now looking for option to delete unused from the org. Which three recommendations should a data architect make is order to reduce the number of records from the org? (Choose 3 answers)
A. Use hard delete in Bulk API to permanently delete records from Salesforce.
B. Use hard delete in batch Apex to permanently delete records from Salesforce.
C. Identify records in objects that have not been modified or used In last 3 years.
D. Use Rest API to permanently delete records from the Salesforce org.
E.
Archive the records in enterprise data warehouse (EDW) before deleting from Salesforce.
Archive the records in enterprise data warehouse (EDW) before deleting from Salesforce.
Explanation:
This question addresses a common scenario of managing org storage limits through a responsible data lifecycle strategy, emphasizing compliance and best practices.
🟢 Why A is Correct:
The Bulk API is the most efficient and recommended tool for performing large-scale data deletion operations in Salesforce. It is specifically designed for processing high volumes of records. Using the "hard delete" option in the Bulk API ensures the records are permanently deleted and moved to the Recycle Bin, which is crucial for actually reclaiming storage space.
🟢 Why C is Correct:
The first and most critical step is to identify which data is truly eligible for deletion. You cannot arbitrarily delete data; you must follow a defined data retention policy. Identifying records that have not been modified or used in the last 3 years (or another business-agreed timeframe) is a standard, defensible criterion for archiving and deletion. This ensures business-critical data is not accidentally removed.
🟢 Why E is Correct:
Before performing any permanent ("hard") delete operation in Salesforce, it is a mandatory best practice for compliance and audit purposes to archive a copy of the data in a secure, long-term storage solution like an Enterprise Data Warehouse (EDW). This creates a permanent record that can be referenced if needed for legal, financial, or historical reasons after the data is removed from the operational Salesforce system.
🔴 Why B is Incorrect (hard delete in batch Apex):
While Batch Apex can delete records, it is a more complex and resource-intensive solution on the Salesforce platform compared to using the external, optimized Bulk API. The Bulk API is the simpler, more standard, and more efficient tool for this specific task of bulk deletion. Batch Apex should be used for more complex logic where data needs to be processed before deletion.
🔴 Why D is Incorrect (REST API):
The standard REST API is not designed for the high-volume deletion of millions of records. It is better suited for real-time, transactional interactions (e.g., creating or updating a few records from a mobile app). Using it for a mass deletion job would be extremely slow and would likely hit API rate limits.
Reference:
Data lifecycle management and storage management are key responsibilities of a Data Architect. The process should always be:
1) Identify data against a policy (C)
2) Archive it (E)
3) Use the most efficient tool to delete it (A)
North Trail Outfitters (NTO) operates a majority of its business from a central Salesforce org, NTO also owns several secondary orgs that the service, finance, and marketing teams work out of, At the moment, there is no integration between central and secondary orgs, leading to data-visibility issues. Moving forward, NTO has identified that a hub-and-spoke model is the proper architect to manage its data, where the central org is the hub and the secondary orgs are the spokes. Which tool should a data architect use to orchestrate data between the hub org and spoke orgs?
A. A middleware solution that extracts and distributes data across both the hub and spokes.
B. Develop custom APIs to poll the hub org for change data and push into the spoke orgs.
C. Develop custom APIs to poll the spoke for change data and push into the org.
D. A backup and archive solution that extracts and restores data across orgs.
Explanation:
This question tests the understanding of integration patterns, specifically the implementation of a hub-and-spoke model for multi-org architectures.
Why A is Correct: A middleware solution (like MuleSoft, Informatica, Jitterbit, etc.) is the ideal tool to orchestrate a complex hub-and-spoke integration pattern. It acts as a central "broker" that can:
⇒ Extract data from the hub (central org) based on events or a schedule.
⇒ Apply transformation logic to make the data suitable for each spoke org.
⇒ Load (distribute) the transformed data to the appropriate spoke orgs.
⇒ Handle errors, retries, and logging across the entire integration flow.
This provides a scalable, maintainable, and monitored integration architecture.
Why B is Incorrect (Custom APIs to poll hub and push to spokes): While technically possible, building a custom API solution is a "build" approach that creates significant long-term maintenance overhead. The custom code would need to handle all aspects of error handling, security, transformation, and routing. A pre-built middleware platform is a "buy" approach that provides these capabilities out-of-the-box and is the recommended best practice.
Why C is Incorrect (Custom APIs to poll spokes and push to hub): This suggests the spokes are the source of truth, which contradicts the defined hub-and-spoke model where the central org is the hub (master). Data should flow from the hub out to the spokes, not be collected from the spokes into the hub in this manner.
Why D is Incorrect (Backup and archive solution): Tools like Data Loader or backup services are for one-time data migration or point-in-time recovery. They are not for ongoing, operational, near-real-time data orchestration between live systems. They lack the transformation, routing, and real-time triggering capabilities needed for this scenario.
Reference: The use of middleware for complex, multi-point integrations is a standard industry pattern. It abstracts the complexity away from individual systems and centralizes the management of data flows.
Get Cloudy Consulting monitors 15,000 servers, and these servers automatically record their status every 10 minutes. Because of company policy, these status reports must be maintained for 5 years. Managers at Get Cloudy Consulting need access to up to one week's worth of these status reports with all of their details. An Architect is recommending what data should be integrated into Salesforce and for how long it should be stored in Salesforce. Which two limits should the Architect be aware of? (Choose two.)
A. Data storage limits
B. Workflow rule limits
C. API Request limits
D. Webservice callout limits
Explanation:
This question requires evaluating a high-volume data scenario and identifying the most constraining platform limits that would be impacted.
✅ Why A is Correct (Data storage limits): This is the most obvious and critical limit.
✔️ Calculation: 15,000 servers * 6 status reports per hour * 24 hours * 7 days = 15,120,000 records per week.
Storing even a single week's worth of this data would consume a massive amount of Salesforce data storage. Storing 5 years' worth (as required by policy) is not feasible in Salesforce. The architect must be aware that this volume of data would quickly exhaust the org's storage allocation.
✅ Why C is Correct (API Request limits): To get the detailed status reports into Salesforce, a high-volume integration would be required. Every attempt to insert 15+ million records per week would consume an enormous number of API requests. Salesforce orgs have 24-hour rolling limits on API calls (which vary by edition). This integration would likely hit those limits, preventing other integrations and tools from functioning.
❌ Why B is Incorrect (Workflow rule limits): Workflow rules are a legacy automation tool and have limits on the number of active rules per object. However, this is not the primary constraint. The sheer volume of data and the API calls needed to bring it in are far more limiting factors.
❌ Why D is Incorrect (Webservice callout limits): Callout limits govern outbound calls from Apex code to external systems. This scenario describes inbound data being sent into Salesforce. Therefore, callout limits are not relevant. The relevant inbound limit is the API Request limit.
Reference: A Data Architect must be able to perform rough "napkin math" to assess the feasibility of storing and integrating large data volumes. This scenario is a classic case where the data should be stored in an external system (like a data lake), and only aggregated summaries or recent exceptions should be integrated into Salesforce.
UC has one SF org (Org A) and recently acquired a secondary company with its own Salesforce org (Org B). UC has decided to keep the orgs running separately but would like to bidirectionally share opportunities between the orgs in near-real time. Which 3 options should a data architect recommend to share data between Org A and Org B? (Choose 3 answers)
A. Leverage Heroku Connect and Heroku Postgres to bidirectionally sync Opportunities.
B. Install a 3rd party AppExchange tool to handle the data sharing
C. Develop an Apex class that pushes opportunity data between orgs daily via the Apex schedule
D. Leverage middleware tools to bidirectionally send Opportunity data across orgs.
E. Use Salesforce Connect and the cross-org adapter to visualize Opportunities into external objects
Explanation:
This question assesses knowledge of the various integration patterns and tools available for bi-directional, near-real-time synchronization between two separate Salesforce orgs.
🟢 Why A is Correct (Heroku Connect):
Heroku Connect is a powerful tool specifically designed for bi-directional sync between a Salesforce org and a Heroku Postgres database. The pattern would be: both Org A and Org B sync bi-directionally with the same Heroku Postgres database, which acts as the integration hub. This provides a robust and scalable solution for near-real-time data sharing.
🟢 Why B is Correct (3rd party AppExchange tool):
The AppExchange offers numerous pre-built applications (e.g., from Informatica, Dell Boomi, MuleSoft, or specialized tools like OwnBackup Replicate) that are designed specifically for org-to-org synchronization. These are excellent "buy" options that can accelerate implementation and reduce maintenance overhead.
🟢 Why D is Correct (Middleware tools):
As with the previous question, using a middleware tool (like MuleSoft, Jitterbit, Informatica) is a standard and highly recommended approach. The middleware would listen for changes in both orgs (via streaming API or polling) and synchronize them bi-directionally, handling transformation and conflict resolution. This provides maximum control and flexibility.
🔴 Why C is Incorrect (Apex class scheduled daily):
A daily scheduled Apex job does not meet the requirement for "near-real time" synchronization. Daily is batch-oriented and would result in significant data latency (up to 24 hours old). This solution also places the processing burden on the Salesforce platform and is more fragile and limit-prone than using a dedicated integration tool.
🔴 Why E is Incorrect (Salesforce Connect cross-org adapter):
Salesforce Connect with the cross-org adapter is an excellent solution, but it is read-only. It allows you to view (or "visualize") records from one org in another org via external objects. It does not support bi-directional synchronization or writing data back to the source org. Therefore, it does not meet the requirement to "bidirectionally share opportunities."
Reference:
The key is to distinguish between read-only solutions (E), batch solutions (C), and true bi-directional near-real-time solutions (A, B, D). Heroku Connect is a particularly important platform tool to know for this use case.
Universal Containers (UC) has an open sharing model for its Salesforce users to allow all its Salesforce internal users to edit all contacts, regardless of who owns the contact. However, UC management wants to allow only the owner of a contact record to delete that contact. If a user does not own the contact, then the user should not be allowed to delete the record. How should the architect approach the project so that the requirements are met?
A. Create a "before delete" trigger to check if the current user is not the owner.
B. Set the Sharing settings as Public Read Only for the Contact object.
C. Set the profile of the users to remove delete permission from the Contact object.
D. Create a validation rule on the Contact object to check if the current user is not the owner.
Explanation:
UC requires full edit access to all Contact records for internal users (via an open sharing model, such as Public Read/Write OWD), but deletion must be restricted to the record owner only. This demands granular control over delete operations without impacting edit or read permissions. Let’s evaluate each option:
Option A: Create a "before delete" trigger to check if the current user is not the owner.
This is the optimal approach. A before delete trigger on the Contact object can use UserInfo.getUserId() to compare the current user's ID against the OwnerId field of the records in Trigger.old. If they do not match, the trigger can call addError() to block the deletion and display a custom message (e.g., "You can only delete Contacts you own"). This enforces the owner-only deletion rule at the record level without altering sharing settings, profiles, or other permissions, preserving the open edit model.
Option B: Set the Sharing settings as Public Read Only for the Contact object.
Changing the Organization-Wide Default (OWD) to Public Read Only would prevent all users from editing Contacts (let alone deleting them), directly conflicting with the requirement for full edit access. This option does not allow selective deletion control.
Option C: Set the profile of the users to remove delete permission from the Contact object.
Removing the "Delete" object permission from user profiles would disable deletion for all Contacts across the board, not just for non-owners. This violates the requirement that owners can still delete their own records and does not provide record-level granularity.
Option D: Create a validation rule on the Contact object to check if the current user is not the owner.
Validation rules execute on insert, update, or upsert (via "before save" context) but do not fire on delete operations. They cannot prevent deletions, making this option ineffective for the requirement.
Why Option A is Optimal:
A before delete trigger provides precise, record-specific enforcement of the owner-only deletion rule while maintaining the open sharing model for reads and edits. This is a standard Salesforce best practice for custom delete restrictions, as declarative tools (e.g., sharing, profiles, validation rules) lack the flexibility for this scenario.
References:
Salesforce Documentation: Apex Triggers - Before Delete Context
Salesforce Developer Blog: Restricting Record Deletion Based on Ownership
Salesforce Architect Guide: Sharing and Permissions
Universal Containers wishes to maintain Lead data from Leads even after they are deleted and cleared from the Recycle Bin. What approach should be implemented to achieve this solution?
A. Use a Lead standard report and filter on the IsDeleted standard field.
B. Use a Converted Lead report to display data on Leads that have been deleted.
C. Query Salesforce with the queryAll API method or using the ALL ROWS SOQL keywords.
D. Send data to a Data Warehouse and mark Leads as deleted in that system.
Explanation:
UC needs a permanent retention strategy for Lead data beyond Salesforce's standard Recycle Bin (which holds deleted records for 15 days before permanent deletion). Once cleared from the Recycle Bin, data is irretrievable via standard Salesforce mechanisms without support intervention (which is limited and not scalable). Let’s analyze each option:
Option A: Use a Lead standard report and filter on the IsDeleted standard field.
The IsDeleted field can be used in SOQL reports to view soft-deleted records (those in the Recycle Bin), but it does not access data after permanent deletion from the Recycle Bin. Once permanently deleted, the records are no longer queryable, making this insufficient for long-term maintenance.
Option B: Use a Converted Lead report to display data on Leads that have been deleted.
Converted Lead reports focus on Leads that have been converted to Accounts/Opportunities/Contacts, not deleted ones. They do not provide visibility into deleted (let alone permanently deleted) Leads and are unrelated to the requirement.
Option C: Query Salesforce with the queryAll API method or using the ALL ROWS SOQL keywords.
queryAll() in the API or ALL ROWS in SOQL retrieves soft-deleted records (in the Recycle Bin) by including IsDeleted = true. However, this does not work for records permanently deleted from the Recycle Bin, as they are no longer stored in Salesforce's database. This approach fails for data cleared from the Recycle Bin.
Option D: Send data to a Data Warehouse and mark Leads as deleted in that system.
This is the best solution. Implement an integration (e.g., via ETL tools, Change Data Capture, or Outbound Messages) to replicate Lead data to an external Data Warehouse (e.g., Snowflake, AWS Redshift) in real-time or near-real-time. When a Lead is deleted in Salesforce, update the warehouse record with a "deleted" flag or soft-delete marker. This ensures permanent retention and accessibility even after Recycle Bin clearance, allowing UC to maintain historical data for compliance, reporting, or auditing without relying on Salesforce's limited recovery options.
Why Option D is Optimal:
Salesforce does not natively support indefinite retention post-Recycle Bin clearance, so external archiving to a Data Warehouse provides a scalable, auditable solution. It aligns with data governance best practices for large-scale orgs, enabling queries on historical Lead data indefinitely while marking deletions appropriately.
References:
Salesforce Documentation: Recycle Bin and Data Recovery
Salesforce Developer Guide: SOQL ALL ROWS Limitations (confirms no access post-permanent deletion)
Salesforce Architect Guide: Data Archiving and Retention
Universal Containers (UC) is implementing Salesforce and will be using Salesforce to track customer complaints, provide white papers on products, and provide subscription based support. Which license type will UC users need to fulfill UC's requirements?
A. Sales Cloud License
B. Lightning Platform Starter License
C. Service Cloud License
D. Salesforce License
Explanation:
UC's use cases center on customer service: tracking complaints (case management), providing white papers (knowledge base for self-service or agent support), and subscription-based support (entitlements and service contracts). The appropriate license must support these service-oriented features. Let’s evaluate each option:
❌ Option A: Sales Cloud License
Sales Cloud focuses on sales processes (e.g., leads, opportunities, forecasting), not service features like case management or knowledge articles for complaints and support. It lacks built-in tools for subscription support or complaint tracking.
❌ Option B: Lightning Platform Starter License
This is a low-cost license for custom app development on the Lightning Platform, with limited access to standard objects like Cases or Knowledge. It does not include service-specific features for complaints, white papers, or subscription support, making it unsuitable.
✅ Option C: Service Cloud License
This is the correct choice. Service Cloud provides comprehensive tools for customer service, including Case object for tracking complaints, Knowledge base for white papers and product documentation, and Entitlements/Contracts for subscription-based support. It enables agents to handle support requests efficiently, aligning perfectly with UC's requirements.
❌ Option D: Salesforce License
"Salesforce License" is not a standard edition; it may refer to the legacy full CRM license (now superseded by Sales or Service Cloud). It does not specifically address service functionalities like complaint tracking or knowledge management.
✅ Why Option C is Optimal:
Service Cloud is designed for customer support scenarios, offering native features for cases (complaints), knowledge articles (white papers), and service entitlements (subscriptions). This ensures UC can implement a unified service platform without needing multiple licenses.
References:
Salesforce Documentation: Service Cloud Overview
Salesforce Help: Case Management and Knowledge
| Page 8 out of 26 Pages |
| 4567891011 |
| Salesforce-Platform-Data-Architect Practice Test Home |
Our new timed 2026 Salesforce-Platform-Data-Architect practice test mirrors the exact format, number of questions, and time limit of the official exam.
The #1 challenge isn't just knowing the material; it's managing the clock. Our new simulation builds your speed and stamina.
You've studied the concepts. You've learned the material. But are you truly prepared for the pressure of the real Salesforce Certified Platform Data Architect - Plat-Arch-201 exam?
We've launched a brand-new, timed Salesforce-Platform-Data-Architect practice exam that perfectly mirrors the official exam:
✅ Same Number of Questions
✅ Same Time Limit
✅ Same Exam Feel
✅ Unique Exam Every Time
This isn't just another Salesforce-Platform-Data-Architect practice questions bank. It's your ultimate preparation engine.
Enroll now and gain the unbeatable advantage of:
Copyright © - All Rights Reserved