Total 250 Questions
Last Updated On : 12-Jun-2026
Preparing with Professional-Cloud-Architect practice test 2026 is essential to ensure success on the exam. It allows you to familiarize yourself with the Professional-Cloud-Architect exam questions format and identify your strengths and weaknesses. By practicing thoroughly, you can maximize your chances of passing the Salesforce certification 2026 exam on your first attempt. Start with free PROFESSIONAL CLOUD ARCHITECT sample questions or use the timed simulator for full exam practice. Surveys from different platforms and user-reported pass rates suggest PROFESSIONAL CLOUD ARCHITECT practice exam users are ~30-40% more likely to pass.

Topic 1, Mountkirk Games Case Study
Company Overview
Mountkirk Games makes online, session-based. multiplayer games for the most popular mobile platforms.
Company Background
Mountkirk Games builds all of their games with some server-side integration and has historically used cloud
providers to lease physical servers. A few of their games were more popular than expected, and they had
problems scaling their application servers, MySQL databases, and analytics tools.
Mountkirk's current model is to write game statistics to files and send them through an ETL tool that loads
them into a centralized MySQL database for reporting.
Solution Concept
Mountkirk Games is building a new game, which they expect to be very popular. They plan to deploy the
game's backend on Google Compute Engine so they can capture streaming metrics, run intensive analytics and
take advantage of its autoscaling server environment and integrate with a managed NoSQL database.
Technical Requirements
Requirements for Game Backend Platform
1. Dynamically scale up or down based on game activity.
2. Connect to a managed NoSQL database service.
3. Run customized Linx distro.
Requirements for Game Analytics Platform
1. Dynamically scale up or down based on game activity.
2. Process incoming data on the fly directly from the game servers
3. Process data that arrives late because of slow mobile networks.
4. Allow SQL queries to access at least 10 TB of historical data.
5. Process files that are regularly uploaded by users' mobile devices.
6. Use only fully managed services
CEO Statement
Our last successful game did not scale well with our previous cloud provider, resuming in lower user adoption
and affecting the game’s reputation. Our investors want more key performance indicators (KPIs) to evaluate
the speed and stability of the game, as well as other metrics that provide deeper insight into usage patterns so
we can adapt the gams to target users.
CTO Statement
Our current technology stack cannot provide the scale we need, so we want to replace MySQL and move to an
environment that provides autoscaling, low latency load balancing, and frees us up from managing physical
servers.
CFO Statement
We are not capturing enough user demographic data usage metrics, and other KPIs. As a result, we do not
engage the right users. We are not confident that our marketing is targeting the right users, and we are not
selling enough premium Blast-Ups inside the games, which dramatically impacts our revenue.
For this question, refer to the Mountkirk Games case study.
Mountkirk Games' gaming servers are not automatically scaling properly. Last month, they rolled out a new feature, which suddenly became very popular. A record number of users are trying to use the service, but many of them are getting 503 errors and very slow response times. What should they investigate first?
A. Verify that the database is online.
B. Verify that the project quota hasn't been exceeded.
C. Verify that the new feature code did not introduce any performance bugs.
D. Verify that the load-testing team is not running their tool against production.
Explanation:
Mountkirk Games is experiencing 503 errors and slow response times after releasing a popular new feature. These symptoms strongly suggest that the backend infrastructure is unable to scale to meet demand. In Google Cloud, one of the most common causes of failed autoscaling is exceeding project-level quotas — which restrict the number of resources (e.g., CPUs, memory, instances) that can be provisioned.
✅ Why B is Correct
503 errors typically indicate that the service is unavailable due to resource exhaustion or backend overload.
Autoscaling failures often result from hitting quotas on compute resources, such as instance count, CPU cores, or regional limits.
Google Cloud enforces quotas to prevent accidental overuse and ensure fair resource distribution. If quotas are exceeded, new instances cannot be provisioned — even if autoscaling is configured correctly.
Verifying quotas is a fast, low-effort first step that can immediately confirm whether scaling is blocked due to resource limits.
Reference:
📘 Google Cloud Quotas Overview
📘 Troubleshooting GKE Autoscaling
❌ Why Other Options Are Incorrect
A. Verify that the database is online
While a downed database could cause errors, it would likely result in 500-series errors related to database connectivity, not widespread 503s tied to scaling. Also, the issue is described as autoscaling failure, not database outage.
Reference:
📘 Cloud SQL Troubleshooting Guide
C. Verify that the new feature code did not introduce any performance bugs
Performance bugs could contribute to latency, but they wouldn’t directly prevent autoscaling or cause 503 errors unless they exhaust resources. This is a valid follow-up investigation, but not the first thing to check when autoscaling fails.
Reference:
📘 Cloud Monitoring and Profiling
D. Verify that the load-testing team is not running their tool against production
This is a speculative scenario. Unless there’s evidence of internal load testing, it’s not the most immediate or likely cause. The issue stems from real user traffic due to a popular feature — not artificial load.
Reference:
📘 Cloud Logging and Audit Logs
Summary:
When autoscaling fails and users receive 503 errors:
First check project quotas — they often silently block resource provisioning.
If quotas are exceeded, autoscaling cannot launch new instances, leading to service unavailability.
Once quotas are ruled out, investigate performance bugs, database health, and internal traffic sources.
For this question, refer to the Mountkirk Games case study.
Mountkirk Games wants to set up a real-time analytics platform for their new game. The new platform must meet their technical requirements. Which combination of Google technologies will meet all of their requirements?
A. Container Engine, Cloud Pub/Sub, and Cloud SQL
B. Cloud Dataflow, Cloud Storage, Cloud Pub/Sub, and BigQuery
C. Cloud SQL, Cloud Storage, Cloud Pub/Sub, and Cloud Dataflow<
D. Cloud Dataproc, Cloud Pub/Sub, Cloud SQL, and Cloud Dataflow
E. Cloud Pub/Sub, Compute Engine, Cloud Storage, and Cloud Dataproc
Explanation:
While the exact technical requirements from the case study aren't listed in your question, the Mountkirk Games case study consistently emphasizes the need for a highly scalable, real-time analytics platform to handle massive, fluctuating volumes of in-game event data for live operations and player analytics.
Let's break down why this combination forms the canonical "real-time analytics" pipeline on Google Cloud and why the other options are inferior.
Analysis of the Correct Stack (Option B):
Cloud Pub/Sub:
This is the ingestion service. It acts as a durable, scalable, and asynchronous message bus. Game clients and servers can publish millions of events per second to a Pub/Sub topic from anywhere in the world without worrying about backpressure or losing data. This is the foundational entry point for any real-time stream processing system.
Cloud Dataflow:
This is the processing service. It is a fully managed stream (and batch) data processing engine. Dataflow can subscribe to the Pub/Sub topic, read the event stream, and perform essential operations in real-time:
Transformation:
Parsing raw event data (e.g., JSON).
Enrichment:
Adding context to events (e.g., looking up player level from a database).
Aggregation:
Calculating metrics like daily active users, in-game purchases per minute, or average session length in real-time.
Windowing:
Grouping events into time-based windows (e.g., 1-minute aggregates).
BigQuery:
This is the analysis and storage service. Dataflow streams the processed results directly into BigQuery. BigQuery is a serverless, highly scalable data warehouse that allows analysts and data scientists to run SQL queries over terabytes of data in seconds. It supports both real-time (streaming) data and historical data, providing a unified view.
Cloud Storage:
This serves as the data lake and reliability backbone. Dataflow can be configured to write raw, unprocessed events from Pub/Sub to Cloud Storage for long-term, cheap storage. This creates a "replayable" history of all events, which is crucial for:
Reprocessing data if logic changes.
Batch training of machine learning models.
Compliance and auditing.
Why the Other Options Are Incorrect:
A. Container Engine, Cloud Pub/Sub, and Cloud SQL:
This lacks a dedicated stream processing engine (Dataflow) and a scalable analytics warehouse (BigQuery). Cloud SQL is a relational database for transactional workloads, not for analyzing petabytes of streaming event data. It would quickly become a bottleneck.
C. Cloud SQL, Cloud Storage, Cloud Pub/Sub, and Cloud Dataflow:
This is very close but substitutes the critical BigQuery with Cloud SQL. As explained above, Cloud SQL is the wrong tool for large-scale analytics, making this architecture non-viable for Mountkirk's scale.
D. Cloud Dataproc, Cloud Pub/Sub, Cloud SQL, and Cloud Dataflow:
This is an overcomplicated and mismatched stack. Cloud Dataproc (managed Hadoop/Spark) is typically used for batch processing, not as a primary real-time engine. Using both Dataflow and Dataproc for the same pipeline is redundant and inefficient. It also retains the problematic Cloud SQL.
E. Cloud Pub/Sub, Compute Engine, Cloud Storage, and Cloud Dataproc:
This relies on managing your own stream processing cluster on Compute Engine or using Dataproc for streaming, which is possible but not "fully managed." This introduces significant operational overhead (cluster management, scaling, patching), which contradicts the benefits of a serverless pipeline like the one in Option B.
Reference
Google Cloud - Reference Architecture:
The architecture described in Option B is the standard Google Cloud reference architecture for real-time analytics and event processing. It is specifically designed for use cases like game analytics, IoT, and clickstream analysis, which perfectly matches Mountkirk Games' profile.
For this question, refer to the Mountkirk Games case study Mountkirk Games needs to create a repeatable and configurable mechanism for deploying isolated application environments. Developers and testers can access each other's environments and resources, but they cannot access staging or production resources. The staging environment needs access to some services from production.
What should you do to isolate development environments from staging and production?
A. Create a project for development and test and another for staging and production.
B. Create a network for development and test and another for staging and production.
C. Create one subnetwork for development and another for staging and production.
D. Create one project for development, a second for staging and a third for production.
Explanation:
Mountkirk Games needs a repeatable and configurable mechanism to deploy isolated environments for development, staging, and production. Developers and testers can access each other’s environments but must be blocked from staging and production, while staging needs limited access to production services. The most effective and scalable way to enforce this isolation is by using separate Google Cloud projects.
✅ Why D is Correct
Project-level isolation: Google Cloud projects are the strongest boundary for resource isolation. IAM policies, billing, quotas, and APIs are scoped per project.
Access control:
You can assign IAM roles so developers/testers only have access to the dev project, while staging and production remain restricted.
Service-level sharing:
Staging can access specific production services via VPC peering, Shared VPC, or IAM-controlled APIs — without full access.
Repeatability:
Using Infrastructure as Code (e.g., Terraform), you can replicate environments across projects with consistent configurations.
Reference:
📘 Google Cloud Resource Hierarchy
Best Practices for Enterprise Organizations
❌ Why Other Options Are Incorrect
A. Create a project for development and test and another for staging and production
This groups unrelated environments together, making it harder to enforce access boundaries. Developers could inadvertently access staging or production resources.
B. Create a network for development and test and another for staging and production
Networks provide IP-level isolation, but they don’t enforce IAM boundaries. Without separate projects, resource access control is weaker and harder to audit.
C. Create one subnetwork for development and another for staging and production
Subnetworks are part of a single VPC and project. This setup doesn’t provide strong isolation or separate IAM scopes. It risks cross-environment access and misconfiguration.
Reference
VPC Networks and Subnetworks
Summary
To isolate environments securely and support controlled access:
Use separate projects for dev, staging, and production.
Apply IAM policies to restrict access.
Use VPC peering or Shared VPC for controlled service sharing.
For this question, refer to the Mountkirk Games case study.
Mountkirk Games wants to set up a continuous delivery pipeline. Their architecture includes many small services that they want to be able to update and roll back quickly. Mountkirk Games has the following >requirements:
• Services are deployed redundantly across multiple regions in the US and Europe.
• Only frontend services are exposed on the public internet.
• They can provide a single frontend IP for their fleet of services.
Deployment artifacts are immutable.
Which set of products should they use?
A. Google Cloud Storage, Google Cloud Dataflow, Google Compute Engine
B. Google Cloud Storage, Google App Engine, Google Network Load Balancer
C. Google Container Registry, Google Container Engine, Google HTTP(s) Load Balancer
D. Google Cloud Functions, Google Cloud Pub/Sub, Google Cloud Deployment Manager
Explanation:
The requirements describe a modern, microservices-based architecture needing a robust deployment and networking solution. Let's map the requirements to the capabilities of the products in each option.
Analysis of Requirements:
Many small services... update and roll back quickly: This points directly to containerized microservices and an orchestration platform.
Deployed redundantly across multiple regions: The solution must support global, multi-regional deployment.
Only frontend services are exposed... single frontend IP: This requires a global load balancer that can present a single IP and route traffic to backend services in different regions.
Deployment artifacts are immutable: This is a core characteristic of container images.
Evaluation of Options:
Why C is Correct:
This combination forms the standard, production-ready stack for microservices on GCP.
google container :
Stores the immutable container images (deployment artifacts). It's integrated and secure.
Google Container Engine (GKE):
The managed Kubernetes service. It is perfectly suited for "many small services."
It allows for easy rolling updates and rollbacks.
It can deploy pods redundantly across multiple regions using multi-zonal or even multi-regional clusters.
It manages the underlying Compute Engine instances.
Google HTTP(s) Load Balancer (GLB): This is a global load balancer.
It provides a single frontend IP address that can be used worldwide.
It can route traffic to backend services (GKE clusters) in multiple regions (US and Europe) based on health, proximity, or other rules.
It ensures only frontend services are exposed; internal services can be kept private within the GKE cluster's network.
Why A is Incorrect:
This stack is for data processing, not for hosting a global microservices application.
Cloud Dataflow is for stream and batch processing, not for serving web traffic or managing service deployments.
Compute Engine alone requires significant manual management for orchestration, scaling, and rolling updates, which contradicts the need for quick updates and rollbacks.
Why B is Incorrect:
This stack is partially viable but has significant drawbacks.
App Engine is a Platform-as-a-Service (PaaS) that simplifies deployment but can be less flexible for complex, multi-service applications compared to GKE. While it supports multiple regions, it's not as inherently suited for a large number of interconnected microservices as a container orchestrator.
The critical flaw is the Network Load Balancer (NLB). An NLB is a regional, pass-through load balancer operating at Layer 4 (TCP/UDP). It cannot provide a single global IP; you would need one NLB per region. The HTTP(s) Load Balancer in Option C is the correct choice for a global, single-IP frontend.
Why D is Incorrect:
This is an event-driven/serverless stack, not a general-purpose microservices platform.
Cloud Functions is a serverless, event-driven compute service for running code in response to events. It is not designed for hosting a fleet of long-running, interconnected microservices that require features like statefulness or specific network configurations.
Cloud Deployment Manager is an infrastructure-as-code tool, which is useful but doesn't solve the runtime orchestration and global load balancing needs. Pub/Sub is for messaging, not service hosting.
Reference
Google Cloud - Microservices Architecture on GKE:
The documentation consistently presents the pattern of Container Registry (for images) + GKE (for orchestration) + Global Load Balancer (for ingress) as the foundational architecture for scalable, resilient microservices.
Google Cloud - HTTP(S) Load Balancing:
The documentation emphasizes its global nature: "External HTTP(S) Load Balancing is a proxy-based Layer 7 load balancer that enables you to run and scale your services worldwide behind a single external IP address."
For this question, refer to the Mountkirk Games case study.
Mountkirk Games has deployed their new backend on Google Cloud Platform (GCP). You want to create a thorough testing process for new versions of the backend before they are released to the public. You want the testing environment to scale in an economical way. How should you design the process?
A. Create a scalable environment in GCP for simulating production load.
B. Use the existing infrastructure to test the GCP-based backend at scale.
C. Build stress tests into each component of your application using resources internal to GCP to simulate load.
D. Create a set of static environments in GCP to test different levels of load — for example, high, medium, and low.
Explanation:
The question asks how Mountkirk Games can design a thorough and economical testing process for their new Google Cloud backend before releasing it to production. The main goal is to test new versions under realistic production conditions while ensuring cost efficiency through scalable infrastructure.
Option A: Create a scalable environment in GCP for simulating production load. ✅
Why it’s correct:
The most effective and economical approach is to create a scalable test environment in Google Cloud that mimics production and can scale up or down dynamically during load testing.
By using GCP’s autoscaling features, resources are provisioned only when needed (e.g., during test execution) and automatically scaled down afterward, minimizing cost.
Key GCP services to use include:
Compute Engine Managed Instance Groups or GKE (Google Kubernetes Engine) for automatic horizontal scaling of backend services.
Cloud Load Balancing to simulate realistic traffic distribution.
Cloud Monitoring and Cloud Logging for performance insights and debugging.
Cloud Deployment Manager or Terraform for repeatable, automated test environment creation.
This approach allows for production-scale testing, cost optimization, and repeatable deployments with minimal manual effort.
You can use Cloud Build, Cloud Scheduler, and Pub/Sub to automate test triggers and teardown, ensuring the environment runs only when necessary.
Benefits:
Scalable: Automatically expands to simulate high user traffic and contracts afterward.
Economical: Pay only for resources used during test execution.
Production-like: Ensures accurate performance validation in an environment similar to production.
Repeatable: Easily reproducible with Infrastructure as Code (IaC).
References:
Google Cloud Load Testing Best Practices
Google Cloud Autoscaler Overview
GKE Autoscaling Concepts
Why the other options are not correct:
B. Use the existing infrastructure to test the GCP-based backend at scale. ❌
Using production infrastructure for load testing is risky and costly.
It can negatively impact real users if tests overload systems or cause downtime.
It also does not ensure isolation between testing and live environments, which violates testing best practices.
The goal is to simulate load in an isolated, scalable environment, not on live infrastructure.
Reference:
Testing Best Practices for Production Environments
C. Build stress tests into each component of your application using resources internal to GCP to simulate load. ❌
Component-level stress testing is valuable, but it does not simulate full-system production load.
The question specifies a need to test the entire backend system (integration-level testing).
Additionally, embedding stress test logic in each component increases complexity, maintenance cost, and coupling between production code and test logic.
It is more efficient to use external tools and scalable environments for end-to-end testing.
Reference:
Google Cloud Application Testing Strategies
D. Create a set of static environments in GCP to test different levels of load — for example, high, medium, and low. ❌
Static environments are inefficient and expensive, as resources remain allocated even when not in use.
They also lack flexibility to dynamically adjust to actual test loads, which can lead to either over-provisioning (wasted cost) or under-provisioning (inaccurate test results).
A scalable, dynamic environment (Option A) provides better cost control and adaptability.
Reference:
Cloud Cost Optimization through Autoscaling
Summary:
The best and most economical approach is to use scalable, cloud-native environments in GCP that dynamically replicate production load. This ensures accurate, cost-effective, and safe testing before public release without affecting live systems.
References:
Google Cloud Load Testing Best Practices
Google Compute Engine Autoscaling Documentation
Google Kubernetes Engine Cluster Autoscaler
Infrastructure as Code (IaC) on Google Cloud
For this question, refer to the Mountkirk Games case study.
Mountkirk Games wants you to design their new testing strategy. How should the test coverage differ from their existing backends on the other platforms?
A. Tests should scale well beyond the prior approaches.
B. Unit tests are no longer required, only end-to-end tests.
C. Tests should be applied after the release is in the production environment.
D. Tests should include directly testing the Google Cloud Platform (GCP) infrastructure.
Explanation:
Mountkirk Games is migrating their backend to Google Cloud Platform (GCP) and needs a new testing strategy. The main focus is to adapt their testing process to the cloud-native environment, which involves validating not just the application code but also the cloud infrastructure, configurations, and integrations with managed services.
Option D: Tests should include directly testing the Google Cloud Platform (GCP) infrastructure. ✅
Why it’s correct:
In cloud environments, testing should extend beyond traditional application-level testing (unit, integration, and end-to-end) to include the cloud infrastructure itself — such as network configurations, IAM roles, APIs, scaling policies, and storage permissions.
GCP resources like Compute Engine, Cloud Storage, Cloud SQL, Pub/Sub, and GKE are part of the application’s runtime environment, so they must be validated to ensure they behave as expected under test conditions.
This approach aligns with Infrastructure as Code (IaC) and DevOps best practices, where infrastructure components are deployed, tested, and verified through automated pipelines.
Testing GCP infrastructure can involve:
Deployment verification (e.g., using Terraform or Deployment Manager validation tests).
Policy and IAM validation (ensuring correct access control).
Performance and scaling verification (confirming autoscalers, load balancers, and Cloud Functions behave as expected).
Monitoring and alert testing (verifying Cloud Monitoring, Logging, and error reporting).
Benefit:
Ensures end-to-end reliability from infrastructure to application layer.
Detects misconfigurations (common in cloud setups) early in CI/CD pipelines.
Builds confidence in deployment automation and compliance readiness.
References:
Google Cloud Testing Strategies
Infrastructure Testing with Terraform and GCP
Site Reliability Engineering (SRE) Testing Principles
Why the other options are not correct:
A. Tests should scale well beyond the prior approaches. ❌
While scalability testing is important, the question specifically asks how the test coverage should differ — not scale capacity.
“Scaling” refers to performance load testing, not test coverage scope.
The coverage difference comes from testing GCP infrastructure components, not from scaling tests.
This option misunderstands the intent of "test coverage," which is about what to test, not how large the test environment is.
Reference:
Performance vs. Coverage Testing
B. Unit tests are no longer required, only end-to-end tests. ❌
Unit testing remains essential in any software testing strategy — including cloud environments.
Unit tests catch logic and coding errors early in development, reducing debugging effort later.
Cloud deployment does not eliminate the need for unit or integration tests; it simply adds new types of infrastructure tests.
Relying only on end-to-end tests increases maintenance cost and makes pinpointing failures harder.
Reference:
Google Testing Blog – The Testing Pyramid
C. Tests should be applied after the release is in the production environment. ❌
This contradicts modern DevOps and CI/CD principles.
Tests must be executed before production deployment to catch bugs early, avoid downtime, and prevent regressions.
Testing after release is risky and can cause service disruptions for live users.
While some canary or monitoring tests occur post-deployment, they supplement — not replace — pre-deployment tests.
Reference:
Continuous Integration and Delivery on Google Cloud
Summary:
Migrating to Google Cloud introduces new layers of dependency and risk — such as IAM permissions, service quotas, API reliability, and autoscaling behavior — that didn’t exist in traditional on-premises or other cloud setups. Therefore, test coverage must expand to include validation of GCP infrastructure components, not just the application logic.
This approach aligns with Google’s Site Reliability Engineering (SRE) and DevOps testing philosophies, ensuring that infrastructure, deployment, and configuration changes are all validated automatically before going live.
References:
Google Cloud – Testing Strategies and Best Practices
Google SRE Book – Testing for Reliability
Terraform and Google Cloud Infrastructure Testing
Google DevOps Tech: Testing in CI/CD
For this question, refer to the TerramEarth case study.
TerramEarth's CTO wants to use the raw data from connected vehicles to help identify approximatelyh when a vehicle in the development team to focus teir failure. You want to allow analysts to centrally query the vehicle data. Which architecture should you recommend?
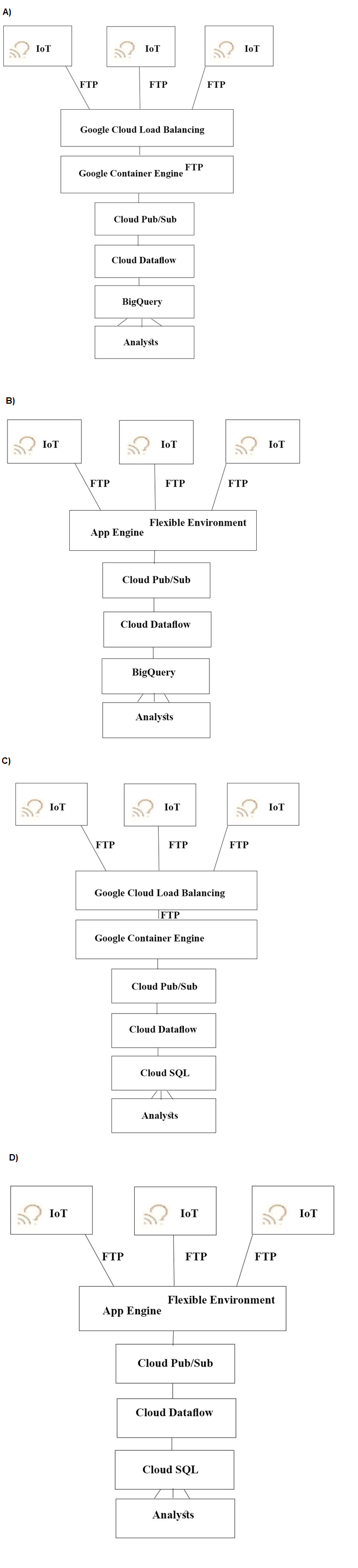
A. Option A
B. Option B
C. Option C
D. Option D
Explanation:
The requirement is to process terabytes of daily IoT vehicle data for predictive analytics and enable centralized SQL querying by analysts. Option A presents the correct, scalable Google Cloud reference architecture for this use case, while the other options contain critical flaws in component selection.
Why Option A is Correct:
The architecture follows the standard pattern for IoT data processing:
GKE with Load Balancing:
A containerized ingestion service on Google Kubernetes Engine (GKE) is ideal for the custom, long-running process of pulling data from FTP servers. The load balancer ensures scalability and high availability.
Pub/Sub for Messaging:
This provides a durable, asynchronous buffer, decoupling the ingestion service from the processing pipeline and handling massive data ingestion rates.
Dataflow for Processing:
This serverless tool is purpose-built for transforming and enriching streaming data (like the vehicle data) in real-time.
BigQuery for Analytics:
This is the correct choice for the data warehouse. It allows analysts to run fast, SQL-based queries on petabyte-scale datasets, directly fulfilling the requirement for "centralized querying."
Why Other Options Are Incorrect:
Option B:
Incorrectly uses App Engine Flexible Environment for data ingestion. App Engine is a Platform-as-a-Service (PaaS) optimized for web applications and has request timeouts and scaling models less suited for robust, long-running backend data-pull processes compared to GKE.
Options C & D:
The critical flaw is using Cloud SQL for the analytical data store. Cloud SQL is a managed relational database for transactional workloads (OLTP). It is not designed for the analytical workload (OLAP) described. With terabytes of data daily, Cloud SQL would be prohibitively expensive, slow, and would hit severe scaling limits. BigQuery is the serverless, petabyte-scale data warehouse designed specifically for this task.
References
Google Cloud Architecture Center - IoT Data Processing:
This reference architecture demonstrates the standard pattern of using Pub/Sub, Dataflow, and BigQuery for IoT analytics.
BigQuery Documentation:
Clearly states it is a "serverless, highly scalable, and cost-effective cloud data warehouse designed for business agility."
For this question refer to the TerramEarth case study Operational parameters such as oil pressure are adjustable on each of TerramEarth's vehicles to increase their efficiency, depending on their environmental conditions. Your primary goal is to increase the operating efficiency of all 20 million cellular and unconnected vehicles in the field How can you accomplish this goal?
A. Have your engineers inspect the data for patterns, and then create an algorithm with rules that make operational adjustments automatically.
B. Capture all operating data, train machine learning models that identify ideal operations, and run locally to make operational adjustments automatically.
C. Implement a Google Cloud Dataflow streaming job with a sliding window, and use Google Cloud Messaging (GCM) to make operational adjustments automatically.
D. Capture all operating data, train machine learning models that identify ideal operations, and host in Google Cloud Machine Learning (ML) Platform to make operational adjustments automatically.
Explanation:
TerramEarth operates 20 million vehicles, many of which are unconnected or have intermittent connectivity. The goal is to increase operating efficiency by adjusting parameters like oil pressure based on environmental conditions. The most effective strategy is to use locally deployed machine learning models that can make real-time decisions without relying on constant cloud connectivity.
✅ Why B Is Correct
Local execution: Running ML models locally ensures that vehicles can make operational adjustments even when offline.
Scalable intelligence:
Once trained in the cloud, models can be deployed to millions of devices to optimize performance autonomously.
Edge compatibility:
This approach aligns with edge computing principles, where inference ha
ppens on-device, reducing latency and dependency on network availability.
Efficiency gains:
Models can continuously adapt to environmental inputs (e.g., altitude, temperature) and optimize parameters like oil pressure for fuel and performance efficiency.
Reference
Google Cloud Edge ML Deployment
ML at the Edge – Google Cloud
❌ Why Other Options Are Incorrect
A. Engineers inspect data and create rule-based algorithms
Rule-based systems lack adaptability and scalability. With 20 million vehicles and diverse environments, manual rules are inefficient and brittle.
C. Dataflow streaming job with GCM
Dataflow is for cloud-based stream processing. GCM (deprecated in favor of Firebase Cloud Messaging) requires connectivity. This setup fails for unconnected vehicles and doesn’t support local decision-making.
Reference
Cloud Dataflow Overview
Firebase Cloud Messaging
D. Host ML models in Google Cloud ML Platform
Hosting models in the cloud requires vehicles to be online to query predictions. This excludes unconnected vehicles and introduces latency and reliability issues.
Reference
📘 Vertex AI (formerly Cloud ML Platform)
Summary
To optimize efficiency across connected and unconnected vehicles, TerramEarth should:
Train ML models centrally using captured operational data.
Deploy models locally to vehicles for offline, real-time adjustments.
For this question, refer to the TerramEarth case study You analyzed TerramEarth's business requirement to reduce downtime, and found that they can achieve a majority of time saving by reducing customers' wait time for parts You decided to focus on reduction of the 3
weeks aggregate reporting time Which modifications to the company's processes should you recommend?
A. Migrate from CSV to binary format, migrate from FTP to SFTP transport, and develop machine learning analysis of metrics.
B. Migrate from FTP to streaming transport, migrate from CSV to binary format, and develop machine learning analysis of metrics.
C. Increase fleet cellular connectivity to 80%, migrate from FTP to streaming transport, and develop machine learning analysis of metrics.
D. Migrate from FTP to SFTP transport, develop machine learning analysis of metrics, and increase dealer local inventory by a fixed factor.
Explanation:
The core problem is reducing the 3-week aggregate reporting time. This delay is caused by the batch-oriented nature of the current process: data is collected in CSV files and transferred weekly via FTP from dealers. To reduce downtime by cutting wait times for parts, the company needs to identify failing parts much faster. The solution must focus on accelerating the data pipeline from data generation to actionable insight.
Let's evaluate the options:
Why B is Correct:
This set of recommendations directly attacks the 3-week delay.
Migrate from FTP to streaming transport: This is the most critical change. Replacing weekly batch FTP transfers with a real-time streaming pipeline (e.g., using Pub/Sub) ensures data is sent to the cloud as soon as it's generated. This eliminates the multi-week latency built into the current process.
Migrate from CSV to binary format:
CSV is a verbose, text-based format. Binary formats (like Protocol Buffers or Avro) are more compact, leading to faster serialization/deserialization and reduced network transfer times. This optimization works in tandem with streaming to make the data pipeline as efficient as possible.
Develop machine learning analysis of metrics:
With data now flowing in near real-time, machine learning models can be applied immediately to identify patterns predictive of part failure. This allows TerramEarth to proactively ship parts to dealers before a vehicle breaks down, directly achieving the goal of reducing customer wait time.
Why A is Incorrect:
While migrating to a binary format and developing ML are good, simply switching from FTP to SFTP (Secure File Transfer Protocol) does not solve the latency problem. SFTP is still a batch-oriented file transfer protocol. It adds security but does not change the fundamental weekly batch cycle. The 3-week aggregate time would remain.
Why C is Incorrect:
Increasing cellular connectivity is a long-term infrastructure project and not a direct process modification for the data pipeline. While more connectivity would provide more data, it doesn't address the core issue of how the data is handled once it is connected. The existing process for connected vehicles still relies on batch FTP transfers from dealers, which is the root cause of the delay. This option is indirect and insufficient on its own.
Why D is Incorrect:
This option combines an ineffective process change (SFTP, which is still batch) with a business outcome (increasing inventory) that is not a data process modification. Increasing inventory by a fixed factor is a costly and inefficient brute-force approach that does not use data intelligently. It does not address the fundamental problem of the slow data reporting pipeline.
Reference
TerramEarth Case Study:
The case study explicitly describes the current "3-week aggregate" delay and attributes it to the process of "dealers upload[ing] the files weekly to a central FTP server." The logical solution is to replace this batch process with a real-time streaming architecture.
Google Cloud - Dataflow & Pub/Sub:
The recommended architecture for real-time analytics involves streaming data ingestion with Pub/Sub and processing with Dataflow, which is what the correct option enables.
For this question, refer to the TerramEarth case study.
TerramEarth's 20 million vehicles are scattered around the world. Based on the vehicle's location its telemetry data is stored in a Google Cloud Storage (GCS) regional bucket (US. Europe, or Asia). The CTO has asked you to run a report on the raw telemetry data to determine why vehicles are breaking down after 100 K miles. You want to run this job on all the data. What is the most cost-effective way to run this job?
A. Move all the data into 1 zone, then launch a Cloud Dataproc cluster to run the job.
B. Move all the data into 1 region, then launch a Google Cloud Dataproc cluster to run the job.
C. Launch a cluster in each region to preprocess and compress the raw data, then move the data into a multi region bucket and use a Dataproc cluster to finish the job.
D. Launch a cluster in each region to preprocess and compress the raw data, then move the data into a regional bucket and use a Cloud Dataproc cluster …..
Explanation:
TerramEarth stores telemetry data in regional GCS buckets across the US, Europe, and Asia. The goal is to analyze all this data cost-effectively to identify why vehicles are failing after 100K miles. The best approach minimizes egress costs and processing overhead by leveraging regional processing first, followed by centralized analysis.
✅ Why D Is Correct
Regional preprocessing:
Launching a Dataproc cluster in each region allows you to process and compress the data locally, avoiding cross-region egress charges.
Reduced data movement:
Compressed data is smaller and cheaper to transfer.
Centralized final analysis:
After preprocessing, move the reduced dataset to a single regional bucket (not multi-region, which is more expensive) and run the final Dataproc job there.
Cost-effective:
This hybrid approach balances compute and storage costs while minimizing network egress fees.
Reference:
Google Cloud Storage Pricing – Network Egress
Dataproc Regional Clusters
❌ Why Other Options Are Incorrect
A. Move all the data into 1 zone, then launch a Cloud Dataproc cluster
❌ Zones are narrower than regions and not designed for cross-region data aggregation. Moving all data to a single zone incurs high egress costs and introduces availability risks.
B. Move all the data into 1 region, then launch a Dataproc cluster
❌ Still incurs significant cross-region egress costs when pulling data from other regions into one. Not cost-effective at scale.
C. Move data into a multi-region bucket after preprocessing
❌ Multi-region buckets are more expensive than regional buckets. Since the final analysis doesn’t require global availability, a regional bucket is more cost-efficient.
Reference
📘 Multi-Region vs Regional Buckets
Summary
To analyze global telemetry data cost-effectively:
Preprocess and compress data in each region using local Dataproc clusters.
Transfer compressed output to a single regional bucket.
Run the final analysis using a Dataproc cluster in that region.
| Page 1 out of 25 Pages |
| 12345678 |
Our new timed 2026 Professional-Cloud-Architect practice test mirrors the exact format, number of questions, and time limit of the official exam.
The #1 challenge isn't just knowing the material; it's managing the clock. Our new simulation builds your speed and stamina.
You've studied the concepts. You've learned the material. But are you truly prepared for the pressure of the real PROFESSIONAL CLOUD ARCHITECT exam?
We've launched a brand-new, timed Professional-Cloud-Architect practice exam that perfectly mirrors the official exam:
✅ Same Number of Questions
✅ Same Time Limit
✅ Same Exam Feel
✅ Unique Exam Every Time
This isn't just another Professional-Cloud-Architect practice questions bank. It's your ultimate preparation engine.
Enroll now and gain the unbeatable advantage of:
Copyright © - All Rights Reserved