Total 250 Questions
Last Updated On : 20-May-2026

Topic 2, TerramEarth Case Study
Company Overview
TerramEarth manufactures heavy equipment for the mining and agricultural industries: About 80% of their
business is from mining and 20% from agriculture. They currently have over 500 dealers and service centers in
100 countries. Their mission is to build products that make their customers more productive.
Company Background
TerramEarth formed in 1946, when several small, family owned companies combined to retool after World
War II. The company cares about their employees and customers and considers them to be extended members
of their family.
TerramEarth is proud of their ability to innovate on their core products and find new markets as their
customers' needs change. For the past 20 years trends in the industry have been largely toward increasing
productivity by using larger vehicles with a human operator.
Solution Concept
There are 20 million TerramEarth vehicles in operation that collect 120 fields of data per second. Data is
stored locally on the vehicle and can be accessed for analysis when a vehicle is serviced. The data is
downloaded via a maintenance port. This same port can be used to adjust operational parameters, allowing the
vehicles to be upgraded in the field with new computing modules.
Approximately 200,000 vehicles are connected to a cellular network, allowing TerramEarth to collect data
directly. At a rate of 120 fields of data per second, with 22 hours of operation per day. TerramEarth collects a
total of about 9 TB/day from these connected vehicles.
Existing Technical Environment
TerramEarth’s existing architecture is composed of Linux-based systems that reside in a data center. These
systems gzip CSV files from the field and upload via FTP, transform and aggregate them, and place the data in
their data warehouse. Because this process takes time, aggregated reports are based on data that is 3 weeks old.
With this data, TerramEarth has been able to preemptively stock replacement parts and reduce unplanned
downtime of their vehicles by 60%. However, because the data is stale, some customers are without their
vehicles for up to 4 weeks while they wait for replacement parts.
Business Requirements
• Decrease unplanned vehicle downtime to less than 1 week, without increasing the cost of carrying surplus
inventory
• Support the dealer network with more data on how their customers use their equipment IP better position
new products and services.
• Have the ability to partner with different companies-especially with seed and fertilizer suppliers in the
fast-growing agricultural business-to create compelling joint offerings for their customers
CEO Statement
We have been successful in capitalizing on the trend toward larger vehicles to increase the productivity of our
customers. Technological change is occurring rapidly and TerramEarth has taken advantage of connected
devices technology to provide our customers with better services, such as our intelligent farming equipment.
With this technology, we have been able to increase farmers' yields by 25%, by using past trends to adjust how
our vehicles operate. These advances have led to the rapid growth of our agricultural product line, which we
expect will generate 50% of our revenues by 2020.
CTO Statement
Our competitive advantage has always been in the manufacturing process with our ability to build better
vehicles for tower cost than our competitors. However, new products with different approaches are constantly
being developed, and I'm concerned that we lack the skills to undergo the next wave of transformations in our
industry. Unfortunately, our CEO doesn't take technology obsolescence seriously and he considers the many
new companies in our industry to be niche players. My goals are to build our skills while addressing
immediate market needs through incremental innovations.
For this question, refer to the TerramEarth case study Your development team has created a structured API to retrieve vehicle data. They want to allow third parties to develop tools for dealerships that use this vehicle event data. You want to support delegated authorization against this data. What should you do?
A. Build or leverage an OAuth-compatible access control system.
B. Build SAML 2.0 SSO compatibility into your authentication system.
C. Restrict data access based on the source IP address of the partner systems.
D. Create secondary credentials for each dealer that can be given to the trusted third party.
Explanation
The goal is to allow third-party tools to access an API on behalf of dealerships. This is a classic scenario for delegated authorization, where a user (the dealership) grants a third-party application limited access to their data without sharing their credentials.
Let's evaluate each option:
Why A is Correct:
OAuth 2.0 is the industry-standard protocol for delegated authorization. It is specifically designed for this use case.
How it works:
A dealership (the resource owner) authenticates with a trusted identity provider (e.g., Google, or TerramEarth's own). The third-party tool (the client) then receives a limited-access token (an access token) that it can use to call the vehicle data API on the dealership's behalf.
Benefits:
It is secure, scalable, and widely adopted. Third-party developers are already familiar with integrating OAuth 2.0. It allows TerramEarth to control what data each third-party tool can access and for which dealership, without ever handling the dealership's login credentials.
Why B is Incorrect:
SAML 2.0 is a protocol for authentication (Single Sign-On), not for delegated API authorization. It is designed to allow a user to log in once and access multiple related web applications (like Google Apps or Salesforce). It is not suited for granting third-party applications programmatic access to a specific API. Using SAML for this would be complex, non-standard, and less secure than OAuth.
Why C is Incorrect:
Restricting access by source IP address is a weak and inflexible form of security.
It does not provide user or application-level authentication. Anyone within the partner's IP range would have access.
It is not scalable, as it requires managing IP whitelists for every third-party developer.
Crucially, it provides no delegation. It cannot distinguish between different dealerships using the same third-party tool. All dealership data accessible to that third party's IP would be exposed, violating data isolation.
Why D is Incorrect:
Creating secondary credentials (shared secrets or usernames/passwords) is a significant security anti-pattern.
Password Proliferation:
Dealers would have to manage multiple sets of credentials.
Lack of Revocation:
If a dealer wants to stop a third party's access, they must change their password, which would break all other integrated tools.
Security Risk:
The third-party tool must store these credentials, creating a massive security risk if they are compromised. It also gives the third party full access to the dealer's account, with no way to limit the scope of access (e.g., "read-only").
No Auditing:
It becomes difficult to audit which application performed a specific action.
Reference:
OAuth 2.0 Framework (RFC 6749):
The official specification defines OAuth 2.0 as "a protocol that allows a user to grant a third-party web site or application access to the user's protected resources, without necessarily revealing their long-term credentials, or even their identity."
Google Cloud - API Security:
Google's own API management platforms (like Apigee and Cloud Endpoints) heavily leverage and recommend OAuth 2.0 for securing API access and enabling third-party ecosystems, which is exactly what TerramEarth needs to build.
For this question, refer to the TerramEarth case study.
To speed up data retrieval, more vehicles will be upgraded to cellular connections and be able to transmit data to the ETL process. The current FTP process is error-prone and restarts the data transfer from the start of the file when connections fail, which happens often. You want to improve the reliability of the solution and minimize data transfer time on the cellular connections. What should you do?
A. Use one Google Container Engine cluster of FTP servers. Save the data to a Multi-Regional bucket. Run the ETL process using data in the bucket.
B. Use multiple Google Container Engine clusters running FTP servers located in different regions. Save the data to Multi-Regional buckets in us, eu, and asia. Run the ETL process using the data in the bucket.
C. Directly transfer the files to different Google Cloud Multi-Regional Storage bucket locations in us, eu,
and asia using Google APIs over HTTP(S). Run the ETL process using the data in the bucket.
D. Directly transfer the files to a different Google Cloud Regional Storage bucket location in us, eu, and asia using Google APIs over HTTP(S). Run the ETL process to retrieve the data from each Regional bucket.
Explanation:
TerramEarth’s goal is to improve reliability and minimize data transfer time over cellular connections, replacing an unreliable FTP process that restarts transfers from the beginning on failure. The best solution must:
Avoid FTP (due to its lack of resumable uploads and poor fault tolerance).
Use resumable, efficient, and reliable transfer protocols.
Minimize latency and cost by storing data close to the source.
✅ Why D is Correct
Regional buckets store data in a specific region, reducing latency and avoiding cross-region egress costs.
Google Cloud Storage supports resumable uploads over HTTP(S), which is ideal for unreliable networks like cellular — uploads can resume from the last byte on failure.
Direct API uploads remove the need for intermediate FTP servers or clusters.
ETL can run regionally or centrally, depending on architecture, but the data is reliably and efficiently collected.
Reference
📘 Resumable Uploads – Cloud Storage
📘 Storage Locations – Regional vs Multi-Regional
❌ Why Other Options Are Incorrect
A. One GKE cluster of FTP servers + Multi-Regional bucket
❌ FTP is unreliable and inefficient over cellular. Multi-regional storage is more expensive and unnecessary for this use case.
B. Multiple GKE clusters with FTP servers + Multi-Regional buckets
❌ Still relies on FTP, which is error-prone. Also, Multi-Regional buckets are costlier and not needed if data is region-specific.
C. Direct transfer to Multi-Regional buckets via HTTP(S)
❌ While HTTP(S) is good, Multi-Regional storage is more expensive and unnecessary. Regional buckets are more cost-effective and performant for localized data ingestion.
Summary:
To improve reliability and reduce transfer time:
Use HTTP(S) with resumable uploads to handle flaky cellular connections.
Store data in regional buckets close to the vehicle’s location.
Avoid FTP and Multi-Regional storage unless global availability is required.
For this question, refer to the TerramEarth case study.
TerramEarth has equipped unconnected trucks with servers and sensors to collet telemetry data. Next year they want to use the data to train machine learning models. They want to store this data in the cloud while reducing costs. What should they do?
A. Have the vehicle’ computer compress the data in hourly snapshots, and store it in a Google Cloud storage (GCS) Nearline bucket.
B. Push the telemetry data in Real-time to a streaming dataflow job that compresses the data, and store it in Google BigQuery.
C. Push the telemetry data in real-time to a streaming dataflow job that compresses the data, and store it in Cloud Bigtable.
D. Have the vehicle's computer compress the data in hourly snapshots, a Store it in a GCS Coldline bucket
Explanation:
The key requirements are:
Data Source: Unconnected trucks (no real-time cellular link).
Primary Goal: Store data in the cloud while reducing costs.
Future Use: The data will be used next year to train machine learning models.
This defines a "cold storage" or "batch upload" scenario where latency is irrelevant, but cost is the primary driver.
Let's evaluate each option:
Why D is Correct:
This is the most cost-effective solution that fits the operational constraints.
Hourly Snapshots:
For unconnected vehicles, real-time streaming is impossible. Batching data into hourly snapshots is the correct approach. Compressing it on the vehicle before any transfer saves on egress costs from the vehicle and storage costs in the cloud.
GCS Coldline Bucket:
Google Cloud Storage Coldline is specifically designed for data that is accessed once per year or less. It has the lowest storage cost among the GCS classes, with a slightly higher cost to access the data. Since the data will be used "next year" for a batch training job, this is the perfect use case for Coldline, minimizing the storage cost for the entire year.
Why A is Incorrect:
The process (hourly snapshots) is correct, but the storage class is wrong. GCS Nearline is for data accessed once per month or less. It is more expensive than Coldline. Using Nearline for data that will sit untouched for a year would incur unnecessary and higher storage costs, violating the primary goal of cost reduction.
Why B is Incorrect:
This option is fundamentally flawed for unconnected vehicles.
Real-time Push:
This is impossible without a continuous network connection.
BigQuery for Raw Storage:
BigQuery is an analytics data warehouse, not a cost-effective raw data lake. Storing raw, compressed telemetry data in BigQuery is significantly more expensive than storing it in Coldline and is not its intended use. You would load the data into BigQuery from GCS when you are ready to analyze it.
Why C is Incorrect:
This option also fails due to the connectivity constraint and cost.
Real-time Push:
Again, not possible for unconnected trucks.
Cloud Bigtable:
Bigtable is a low-latency, high-throughput NoSQL database. It is optimized for real-time access and serving, not for cheap long-term storage of historical data. Its storage costs are much higher than GCS Coldline, making it the most expensive and least suitable option for this batch-oriented, cost-saving requirement.
Reference
Google Cloud Storage Classes:
The official documentation clearly defines the use cases and cost structure for the different storage classes. Coldline is recommended for "data you plan to read or modify on average once per year or less. Ideal for... data archiving."
Data Lifecycle on Google Cloud:
Best practices dictate moving data to the most cost-effective storage tier based on its access patterns. For data that will not be used for 12 months, Coldline is the explicit recommendation.
For this question refer to the TerramEarth case study.
Which of TerramEarth's legacy enterprise processes will experience significant change as a result of increased Google Cloud Platform adoption.
A. Opex/capex allocation, LAN changes, capacity planning
B. Capacity planning, TCO calculations, opex/capex allocation
C. Capacity planning, utilization measurement, data center expansion
D. Data Center expansion, TCO calculations, utilization measurement
Explanation:
TerramEarth’s shift to Google Cloud Platform (GCP) will significantly impact several legacy enterprise processes — especially those tied to infrastructure ownership, cost modeling, and scalability. The most affected areas are:
✅ Why B Is Correct
Capacity Planning: In the cloud, capacity is elastic and on-demand. Traditional long-term forecasting and hardware provisioning are replaced by autoscaling and usage-based planning.
TCO Calculations:
Total Cost of Ownership shifts from hardware, facilities, and maintenance to cloud service consumption. GCP introduces new cost models (e.g., sustained use discounts, per-second billing) that require updated financial analysis.
Opex/Capex Allocation:
Cloud adoption moves spending from capital expenditures (CapEx — buying servers) to operational expenditures (OpEx — paying for usage). This changes budgeting, procurement, and accounting processes.
Reference:
📘 Google Cloud Enterprise Best Practices
📘 Cloud Financial Management
❌ Why Other Options Are Incorrect
A. LAN changes LAN
architecture may evolve, but it’s not a primary enterprise process impacted by cloud migration. Most changes occur at the WAN or interconnect level.
C. Utilization measurement
While cloud platforms offer granular usage metrics, this is a tooling shift — not a fundamental enterprise process change.
D. Data center expansion
GCP adoption reduces the need for physical data center growth, but the process itself is not transformed — it’s simply deprecated.
Summary
TerramEarth’s move to GCP transforms how they plan, budget, and evaluate infrastructure:
Capacity planning becomes dynamic.
TCO modeling shifts to cloud economics.
OpEx/CapEx accounting realigns with service-based consumption.
For this question, refer to the TerramEarth case study.
TerramEarth plans to connect all 20 million vehicles in the field to the cloud. This increases the volume to 20 million 600 byte records a second for 40 TB an hour. How should you design the data ingestion?
A. Vehicles write data directly to GCS.
B. Vehicles write data directly to Google Cloud Pub/Sub.
C. Vehicles stream data directly to Google BigQuery.
D. Vehicles continue to write data using the existing system (FTP).
Explanation:
The scenario describes a massive increase in data volume: 20 million records per second, totaling 40 TB per hour. This is a classic high-throughput, real-time data ingestion problem. The solution must be highly scalable, durable, and capable of decoupling the data producers (vehicles) from the consumers (data processing services).
Let's evaluate each option:
Why B is Correct:
Cloud Pub/Sub is the purpose-built service for this exact scenario.
Scalability:
Pub/Sub is designed to handle ingestion rates of millions of messages per second globally. It can automatically scale to accept the 20 million records/sec without any pre-provisioning.
Durability and Reliability:
It provides persistent, reliable message storage. If the downstream processing system fails or is slow, Pub/Sub will hold the messages until the system recovers, preventing data loss.
Decoupling:
It acts as a "shock absorber" for the data pipeline. Vehicles can publish data as fast as they generate it, independent of how fast the backend systems (like Dataflow or BigQuery) can process it. This isolation is critical for system stability.
Integration:
It seamlessly integrates with Google Cloud's data processing services like Dataflow, which can then subscribe to the topic, process the data, and load it into destinations like BigQuery, Cloud Storage, or Bigtable.
Why A is Incorrect:
Having millions of vehicles write directly to Google Cloud Storage (GCS) is not feasible or efficient.
Inefficient for Small Writes:
GCS is optimized for large objects, not for millions of tiny, individual 600-byte writes per second. The overhead of establishing a connection and creating an object for each record would be enormous and would quickly hit request rate limits.
Lack of Real-Time Processing:
Writing to GCS creates discrete files. This introduces latency, as a file must be closed before it can be processed. It does not support a real-time streaming pipeline.
Why C is Incorrect:
Streaming data directly to BigQuery is strongly discouraged and would fail at this scale.
Cost and Quotas:
BigQuery streaming inserts have quotas and costs associated with them. Ingesting 20 million records per second would massively exceed these quotas and be prohibitively expensive.
Improper Use Case:
BigQuery is an analytical warehouse, not a data ingestion bus. The correct pattern is to stream data into Pub/Sub, process it (e.g., with Dataflow), and then batch load the results into BigQuery for efficiency and cost-effectiveness.
Why D is Incorrect:
Continuing to use the existing FTP system is a recipe for catastrophic failure.
Lack of Scalability:
FTP servers are not designed to handle connections from 20 million concurrent clients or an ingestion rate of 40 TB/hour. The system would collapse under the load.
Management Overhead:
Managing a global fleet of FTP servers to handle this scale would be an operational nightmare, requiring constant scaling, patching, and monitoring, defeating the purpose of using managed cloud services.
Reference
Google Cloud - Pub/Sub Documentation:
Explicitly states that Pub/Sub is designed for "streaming analytics and data integration pipelines to ingest and distribute data." It is the foundational service for building event-driven systems and handling high-volume data streams.
Google Cloud Architecture Center - IoT Data Processing:
The standard reference architecture for IoT and telemetry data always uses Pub/Sub as the ingestion point, followed by Dataflow for processing, and then storage in BigQuery, Bigtable, or GCS.
Your agricultural division is experimenting with fully autonomous vehicles.
You want your architecture to promote strong security during vehicle operation.
Which two architecture should you consider?
Choose 2 answers:<
A. Treat every micro service call between modules on the vehicle as untrusted.
B. Require IPv6 for connectivity to ensure a secure address space.
C. Use a trusted platform module (TPM) and verify firmware and binaries on boot.
D. Use a functional programming language to isolate code execution cycles.
E. Use multiple connectivity subsystems for redundancy.
F. Enclose the vehicle's drive electronics in a Faraday cage to isolate chips.
Explanation:
Fully autonomous vehicles require zero-trust security, hardware-level integrity, and tamper-proof operations to ensure safety, reliability, and protection against cyber threats. In such architectures, every component — both hardware and software — must be verified and isolated to prevent compromise or unauthorized access.
Option A: Treat every microservice call between modules on the vehicle as untrusted. ✅
Why it’s correct:
This aligns with Zero Trust Architecture (ZTA) principles, where no communication is implicitly trusted, even between internal components.
In an autonomous vehicle, multiple microservices handle critical operations such as navigation, object detection, telemetry, and braking systems.
Treating inter-service calls as untrusted ensures that every request is authenticated, authorized, and encrypted — minimizing risks of lateral movement if one module is compromised.
Common methods include mutual TLS (mTLS) for secure communication, service identity verification, and API-level authorization.
Benefits:
Prevents internal spoofing or privilege escalation.
Ensures secure inter-module communication on the vehicle’s internal network.
Reduces the risk of compromised modules affecting critical systems.
Reference:
Google Cloud – BeyondCorp and Zero Trust Security Model
NIST SP 800-207 – Zero Trust Architecture
Option C: Use a Trusted Platform Module (TPM) and verify firmware and binaries on boot. ✅
Why it’s correct:
TPM (Trusted Platform Module) provides hardware-based security for verifying system integrity before the operating system starts.
During boot, Secure Boot uses TPM to verify digital signatures of firmware and binaries. If any unauthorized change is detected, the system halts or switches to a recovery state.
This prevents rootkits, firmware tampering, or unauthorized code execution, which is critical for safety-critical systems like autonomous vehicles.
TPM also helps store encryption keys securely and enable attestation — proving to a central control system that the vehicle’s software stack is authentic.
Benefits:
Ensures system integrity from the hardware up.
Protects against firmware attacks or malicious updates.
Supports cryptographic attestation for remote security checks.
Reference:
Trusted Computing Group – TPM Overview
Google Cloud IoT Security Best Practices
Why the other options are not correct:
B. Require IPv6 for connectivity to ensure a secure address space. ❌
IPv6 provides a larger address space, but it does not inherently enhance security.
Security depends on authentication, encryption, and access controls, not on the IP version.
Autonomous vehicles often use private network protocols or message buses (CAN, DDS, MQTT), which don’t benefit from IPv6 in terms of security.
D. Use a functional programming language to isolate code execution cycles. ❌
While functional programming promotes deterministic and side-effect-free code, it is not a core architectural security mechanism.
Language choice influences reliability and maintainability but does not ensure runtime or hardware-level security needed for autonomous operation.
E. Use multiple connectivity subsystems for redundancy. ❌
Redundant connectivity (e.g., LTE, 5G, satellite) improves availability, not security.
It may even expand the attack surface if additional interfaces are exposed.
The question explicitly focuses on strong security, not reliability or fault tolerance.
F. Enclose the vehicle's drive electronics in a Faraday cage to isolate chips. ❌
A Faraday cage protects against electromagnetic interference (EMI), not cybersecurity threats.
It offers physical protection, but does not secure firmware, APIs, or communication channels between modules.
References:
NIST SP 800-207 – Zero Trust Architecture
Google BeyondCorp: Zero Trust Security Model
Trusted Computing Group – TPM Specification Overview
Google Cloud IoT Security Best Practices
For this question, refer to the TerramEarth case study.
The TerramEarth development team wants to create an API to meet the company's business requirements. You want the development team to focus their development effort on business value versus creating a custom framework. Which method should they use?
A. Use Google App Engine with Google Cloud Endpoints. Focus on an API for dealers and partners.
B. Use Google App Engine with a JAX-RS Jersey Java-based framework. Focus on an API for the public.
C. Use Google App Engine with the Swagger (open API Specification) framework. Focus on an API for the public.
D. Use Google Container Engine with a Django Python container. Focus on an API for the public.
E. Use Google Container Engine with a Tomcat container with the Swagger (Open API Specification) framework. Focus on an API for dealers and partners
Explanation:
TerramEarth wants to build an API that meets business requirements while allowing the development team to focus on business logic, not infrastructure or custom frameworks. The goal is to deliver value quickly and securely — especially for dealers and partners, not the general public.
✅ Why A Is Correct
Google App Engine is a fully managed platform-as-a-service (PaaS) that abstracts away infrastructure concerns like scaling, patching, and load balancing.
Google Cloud Endpoints provides a lightweight, managed API gateway that supports authentication, monitoring, and quota enforcement — ideal for partner-facing APIs.
This combination allows developers to focus on business logic, not boilerplate or framework setup.
It’s optimized for internal/external partner APIs with secure access control via API keys or OAuth.
Reference
📘 Google Cloud Endpoints Overview
📘 App Engine Standard Environment
❌ Why Other Options Are Incorrect
B. JAX-RS Jersey on App Engine
❌ Adds unnecessary complexity. Requires manual framework setup and doesn’t leverage Cloud Endpoints for API management.
C. Swagger on App Engine
❌ Swagger (OpenAPI) is a spec, not a runtime framework. It helps define APIs but doesn’t replace the need for an API gateway or runtime management.
D. Django on Google Kubernetes Engine (GKE)
❌ GKE requires container orchestration and infrastructure management. Overkill for a simple API, and distracts from business logic.
E. Tomcat with Swagger on GKE
❌ Similar to D — adds operational overhead and complexity. Not ideal when the goal is rapid delivery and minimal infrastructure burden.
Summary
To build a secure, scalable API for dealers and partners with minimal overhead:
Use App Engine for managed hosting.
Use Cloud Endpoints for API management and security.
For this question, refer to the JencoMart case study.
JencoMart has built a version of their application on Google Cloud Platform that serves traffic to Asia. You want to measure success against their business and technical goals. Which metrics should you track?
Error rates for requests from Asia
A. Latency difference between US and Asia
B. Total visits, error rates, and latency from Asia
C. Total visits and average latency for users in Asia
D.
The number of character sets present in the database
Explanation:
JencoMart’s application now serves traffic in Asia. To evaluate success against their business and technical goals, you need to track metrics that reflect:
User engagement (business goal)
System reliability and performance (technical goals)
✅ Why B Is Correct
Total visits measure user adoption and traffic volume — a key business indicator.
Error rates directly reflect system reliability and help identify issues like failed requests or service outages
.
Latency affects user experience and is critical for performance benchmarking in the target region (Asia).
Together, these metrics provide a comprehensive view of how well the application is performing and being received in Asia.
Reference
📘 Google Cloud Monitoring Best Practices
📘 SRE Metrics – Google’s Four Golden Signals
❌ Why Other Options Are Incorrect
A. Latency difference between US and Asia
❌ Only compares performance across regions — doesn’t measure adoption or reliability in Asia.
C. Total visits and average latency for users in Asia
❌ Omits error rates, which are essential for tracking system health and diagnosing failures.
D. Number of character sets in the database
❌ Irrelevant to performance or business success. This is a low-level data detail, not a strategic metric.
Summary
To measure success for JencoMart’s Asia deployment:
Track total visits for engagement.
Monitor error rates for reliability.
Measure latency for performance.
For this question, refer to the JencoMart case study.
The migration of JencoMart’s application to Google Cloud Platform (GCP) is progressing too slowly. The infrastructure is shown in the diagram. You want to maximize throughput. What are three potential bottlenecks? (Choose 3 answers.)
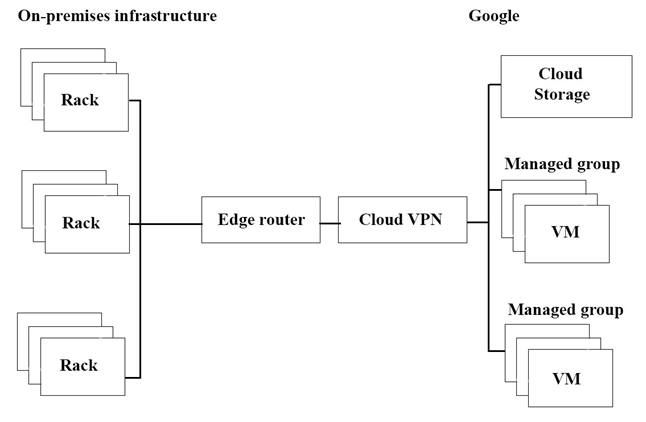
A. A single VPN tunnel, which limits throughput
B. A tier of Google Cloud Storage that is not suited for this task
C. A copy command that is not suited to operate over long distances
D. Fewer virtual machines (VMs) in GCP than on-premises machines
E. A separate storage layer outside the VMs, which is not suited for this task
F. Complicated internet connectivity between the on-premises infrastructure and GCP
Explanation:
JencoMart’s slow migration to Google Cloud Platform (GCP) suggests infrastructure-level bottlenecks that are limiting throughput. Based on the hybrid architecture shown (on-premises connected via Cloud VPN to GCP), the most likely culprits are:
✅ A. A single VPN tunnel, which limits throughput
Cloud VPN has bandwidth limitations (typically up to 3 Gbps per tunnel).
A single tunnel can become a bottleneck during large-scale data transfers.
Scaling requires multiple tunnels or Dedicated Interconnect.
Reference
📘 Cloud VPN Throughput Limits
✅ B. A tier of Google Cloud Storage that is not suited for this task
Using Coldline or Archive tiers for active migration workloads can slow access and increase latency.
Migration tasks require Standard or Nearline tiers optimized for frequent access and faster performance.
Reference
📘 GCS Storage Classes Comparison
✅ C. A copy command that is not suited to operate over long distances
Tools like cp or rsync over long-haul networks can be inefficient due to latency and lack of parallelism.
GCP recommends using gsutil -m or Transfer Appliance for large-scale transfers.
Reference
📘 gsutil Performance Tips
❌ Why Other Options Are Incorrect
D. Fewer VMs in GCP than on-premises machines
❌ VM count alone doesn’t determine throughput. GCP VMs can scale vertically or horizontally, and performance depends more on configuration than raw count.
E. A separate storage layer outside the VMs, which is not suited for this task
❌ GCP storage is designed to be decoupled from compute. Using Cloud Storage or Persistent Disks is standard practice and not inherently a bottleneck.
F. Complicated internet connectivity between on-premises and GCP
❌ The diagram shows a Cloud VPN, which bypasses public internet routing. Unless misconfigured, this isn’t a primary bottleneck.
Summary
To maximize migration throughput, JencoMart should:
Add multiple VPN tunnels or upgrade to Dedicated Interconnect.
Use Standard-tier Cloud Storage for active workloads.
Replace inefficient copy tools with gsutil -m or Transfer Appliance.
For this question, refer to the JencoMart case study.
JencoMart has decided to migrate user profile storage to Google Cloud Datastore and the application servers to Google Compute Engine (GCE). During the migration, the existing infrastructure will need access to Datastore to upload the data. What service account key-management strategy should you recommend?
A. Provision service account keys for the on-premises infrastructure and for the GCE virtual machines (VMs).
B. Authenticate the on-premises infrastructure with a user account and provision service account keys for the VMs
C. Provision service account keys for the on-premises infrastructure and use Google Cloud Platform (GCP) managed keys for the VMs
D. Deploy a custom authentication service on GCE/Google Container Engine (GKE) for the on-premises infrastructure and use GCP managed keys for the VMs
Explanation:
The scenario involves a hybrid environment during migration:
On-premises infrastructure needs temporary access to Cloud Datastore to upload data.
GCE VMs in Google Cloud will need permanent access to Cloud Datastore.
The key-management strategy must balance security and practicality for these two different environments.
Let's evaluate each option:
Why C is Correct:
This strategy uses the most secure option for each environment.
For On-premises:
Services running outside of Google Cloud cannot leverage the automatic, managed identity of a service account. The only way for them to authenticate as a service account is by using a provisioned service account key (a JSON key file). While these keys are long-lived credentials and pose a security risk, they are the necessary solution for this temporary, migration-specific need. The keys should be securely stored and deleted immediately after the migration is complete.
For GCE VMs:
This is the best practice. GCE VMs can be assigned a service account at creation. The platform automatically manages the authentication using short-lived credentials, and no key files are ever downloaded or stored on the VM. This is far more secure than using static keys and is the recommended approach for all workloads running within Google Cloud.
Why A is Incorrect:
This strategy is insecure because it uses service account keys for the GCE VMs. Since the VMs are inside Google Cloud, they should use the built-in, managed identity. Manually provisioning and managing keys on VMs is an anti-pattern that introduces an unnecessary and persistent security risk.
Why B is Incorrect:
This strategy is inconsistent and insecure.
Using a user account for the on-premises infrastructure is poor practice. User accounts are for human users, not for machine identities. They are tied to an individual, which breaks accountability, and their access can be revoked if the person leaves the company.
It also repeats the error of using service account keys for GCE VMs, which is insecure.
Why D is Incorrect:
This is an overly complex and unnecessary solution.
Deploying a custom authentication service adds significant development and operational overhead for a temporary migration task.
The on-premises systems would then authenticate to this custom service, which would in turn need credentials to access Datastore, creating an indirect and more fragile chain of trust. The straightforward and standard method is to use a service account key for the limited duration of the migration.
Reference:
Google Cloud - Service Account Best Practices:
The documentation explicitly advises: "Avoid using service account keys whenever possible." For workloads on GCE, GKE, etc., you should use the managed service account. It also states, "If you must use a service account key, ... rotate and delete the keys frequently."
Google Cloud - Authenticating from outside Google Cloud:
The documentation for scenarios like this specifies that for "workloads running on-premises or on another cloud provider," you must download a private key to use for authentication. This validates the need for a temporary key for the on-premises portion.
| Page 2 out of 25 Pages |
| 12345678 |
| Professional-Cloud-Architect Practice Test Home |
Our new timed 2026 Professional-Cloud-Architect practice test mirrors the exact format, number of questions, and time limit of the official exam.
The #1 challenge isn't just knowing the material; it's managing the clock. Our new simulation builds your speed and stamina.
You've studied the concepts. You've learned the material. But are you truly prepared for the pressure of the real PROFESSIONAL CLOUD ARCHITECT exam?
We've launched a brand-new, timed Professional-Cloud-Architect practice exam that perfectly mirrors the official exam:
✅ Same Number of Questions
✅ Same Time Limit
✅ Same Exam Feel
✅ Unique Exam Every Time
This isn't just another Professional-Cloud-Architect practice questions bank. It's your ultimate preparation engine.
Enroll now and gain the unbeatable advantage of:
Copyright © - All Rights Reserved