Total 202 Questions
Last Updated On : 8-Jul-2026

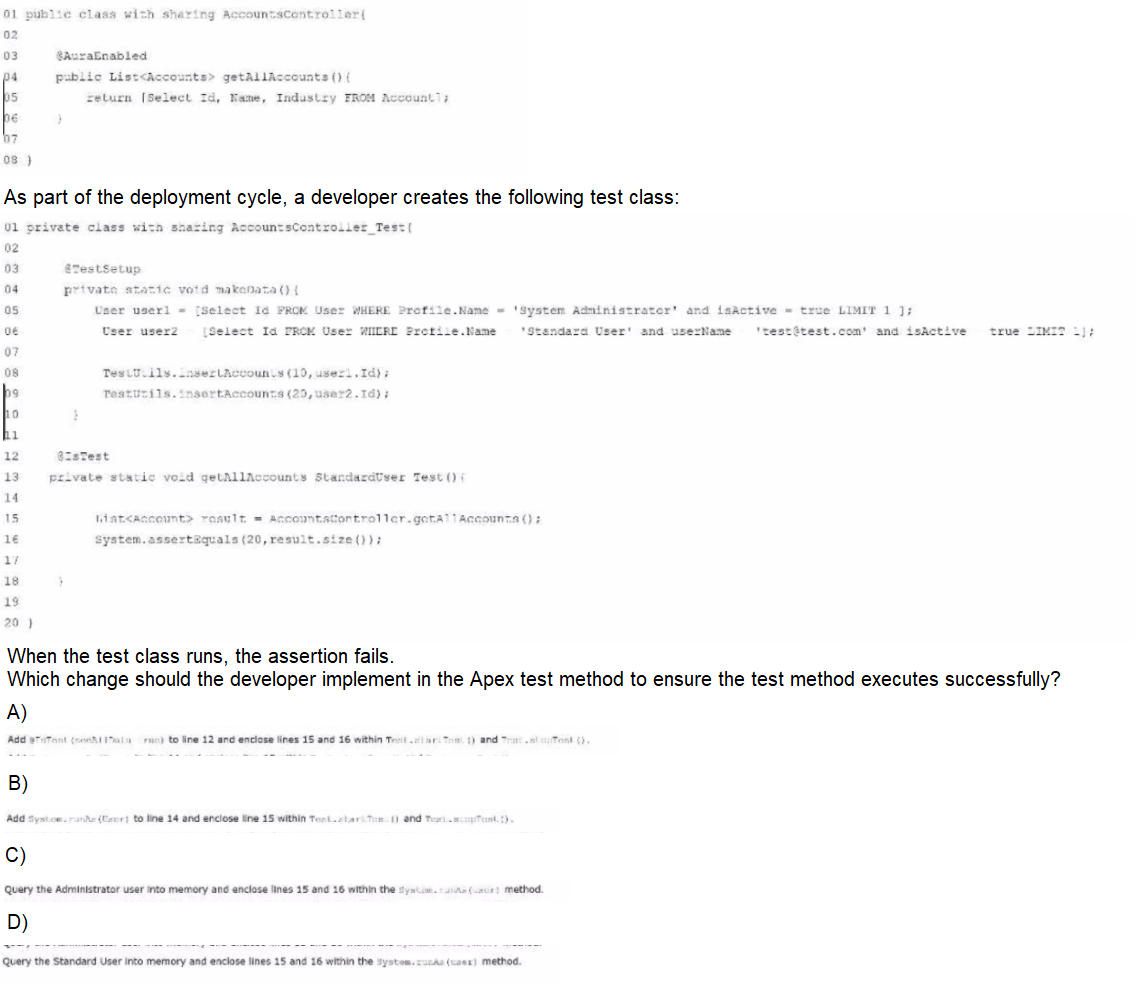
Consider the following code snippet:
A. Option A
B. Option B
C. Option C
D. Option D
Explanation:
📌 Why A is Correct
The issue lies in test execution context and sharing rules. When the test method runs, it executes in the context of the default test user (a system context user), not the intended “Standard User” (user2). The method AccountController.getAllAccounts() performs a SOQL query that’s affected by the sharing rules of the user executing the query.
In Salesforce, when using with sharing in an Apex class (as seen in AccountController), the query obeys object-level sharing rules. Therefore, the number of records returned by getAllAccounts() depends on what records the current user can access.
In the test, you create 20 records assigned to user2, but unless you run the query as user2, your test won't see them — hence the assertion fails (result.size() ≠ 20).
🔁 How to Fix It:
→ Use System.runAs(user2) to simulate the Standard User.
→ Enclose the logic inside Test.startTest() and Test.stopTest() to ensure the governor limits are reset and asynchronous operations (if any) are executed in a controlled context.
📘 Updated Code Snippet (Conceptually):
System.runAs(user2) {
Test.startTest();
List
Test.stopTest();
System.assertEquals(20, result.size());
}
This will correctly simulate user2’s context, and since all 20 accounts were inserted with user2's ownership, the query returns them.
❌ Why Other Options Are Incorrect
B — Add System.runAs(user1) and Test.startTest()
🔴 Why it's wrong:
→ Using user1, the System Administrator, would cause the controller to return all accounts — but your test specifically created 20 accounts tied to user2 (Standard User). Using user1 would not assert the intended user access model and defeats the purpose of testing sharing-based logic.
C — Query the Administrator and enclose lines 15–16 within System.runAs(user1)
🔴 Why it's wrong:
→ Running the test as a System Administrator means full access to all data, regardless of sharing rules. This doesn’t reflect the actual permissions of a Standard User and therefore doesn’t verify sharing behavior, which is the goal of this test.
D — Query Standard User into memory and use System.runAs(user2) in a @testSetup method
🟡 Partially valid idea, but:
→ You cannot use System.runAs() inside @testSetup methods — it will throw an error. According to Salesforce documentation, System.runAs() is only allowed inside test methods, not setup blocks.
→ The test data (like user2) should be created in @testSetup, but context simulation (System.runAs) must be handled in the test method itself.
Reference:
Using the runAs Method
Testing Best Practices
Refer to the following code snippet: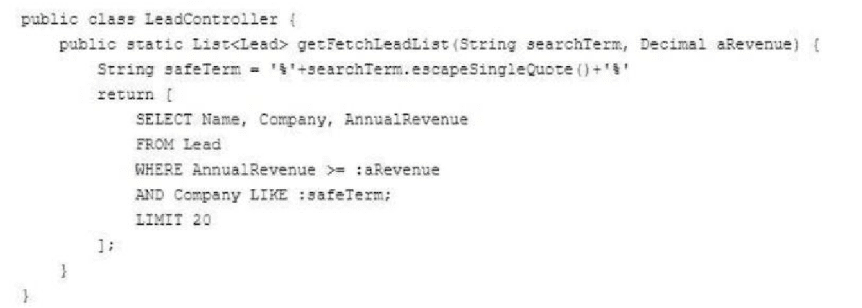
A developer created a JavaScript function as part of a Lightning web component (LWC)
that surfaces information about Leads by wire calling geyFetchLeadList whencertain criteria
are met.
Which three changes should the developer implement in the Apex class above to ensure
the LWC can display data efficiently while preserving security?
(Choose 3 answers)
A. Annotate the Apex method with @AuraEnabled.
B. Implement the with sharing keyword in the class declaration.
C. Implement the with keyword in the class declaration.
D. Use the WZ E D clause within the SOQL query.
E. Annotate the Apex method with @AuraEnabled(Cacheable=True).
Explanation:
✅ A. Annotate the Apex method with @AuraEnabled
→ Why: Lightning Web Components need Apex methods exposed to be callable.
→ The @AuraEnabled annotation makes the method accessible from the frontend.
→ For @wire usage in LWC, this annotation is required.
@AuraEnabled
public static List
✅ B. Implement the with sharing keyword in the class declaration
→ Why: This enforces organization-wide default sharing rules, ensuring that users only see data they have access to.
→ Without with sharing, the class runs in system mode, which could expose sensitive data the user shouldn’t see.
public with sharing class LeadController { ... }
✅ E. Annotate the Apex method with @AuraEnabled(cacheable=true)
→ Why: Makes the method compatible with @wire in LWC and improves performance by caching results.
→ Required for read-only, idempotent operations like querying data (as in this case).
→ Reduces server load and speeds up LWC rendering.
@AuraEnabled(cacheable=true)
public static List
❌ C. Implement the with keyword in the class declaration
》 Why it's incorrect: There’s no with keyword on its own in Apex. It must be with sharing or without sharing. So this option is invalid syntax.
❌ D. Use the WITH SECURITY_ENFORCED clause within the SOQL query
Why it’s not required here:
》 WITH SECURITY_ENFORCED is only supported on certain object types and only applies to field- and object-level access.
》 Since the class will use with sharing, and no restricted fields are being queried, this is not necessary here — though optionally good for enhanced security.
A. Apex REST
B. Client_side validation
C. Custom validation rules
D. Next Best Action
Explanation:
✅ Correct Answer: B. Client-side validation
🧠 Why:
Using client-side validation in a Lightning Web Component (LWC) enables you to validate multiple fields simultaneously before they are sent to the server. This allows the component to display all relevant error messages at once, improving user experience by reducing the number of failed attempts due to one-at-a-time feedback.
Lightning components like
this.template.querySelectorAll('lightning-input').forEach(input => {
input.reportValidity(); // shows validation message if invalid
});
This approach allows you to:
✅ Validate multiple fields at once.
✅ Display multiple error messages.
✅ Avoid unnecessary server calls if validation fails.
❌ Why the Others Are Wrong:
❌ A. Apex REST
➳ Incorrect because Apex REST is used for building custom web service APIs.
➳ It is not relevant to client-side validation or user input handling in LWC.
❌ C. Custom validation rules
➳ Salesforce Validation Rules only fire after the save attempt, i.e., on the server-side.
➳ They return one error per field and may stop the save if a single rule fails, resulting in sequential error discovery.
➳ Cannot display multiple field-level errors at once in LWC easily.
❌ D. Next Best Action
➳ This is a tool for delivering recommendations and flows, typically in Einstein or automation scenarios.
➳ Not intended for form validation or managing field errors in LWC.
🔧 Reference:
Lightning Web Component Validation — Salesforce Developers
Universal Containers needs to integrate with their own, existing, internal custom web application. The web application accepts JSON payloads, resizes product images, and sends the resized images back to Salesforce. What should the developer use to implement this integration?
A. An Apex trigger that calls an @future method that allows callouts
B. A platform event that makes a callout to the web application
C. A flow that calls an @future method that allows callouts
D. A flow with an outbound message that contains a session ID
Explanation:
✅ Correct Answer: A. An Apex trigger that calls an @future method that allows callouts
🧠 Why:
Salesforce does not allow callouts directly from triggers, because HTTP requests are considered long-running operations and can block the transaction. To work around this, the standard and supported solution is to use an @future(callout=true) method, which executes asynchronously after the trigger finishes.
This allows Salesforce to:
→ Trigger the image resize process automatically (e.g., after a product image is uploaded).
→ Call out to the internal web application (which accepts and returns JSON).
→ Handle asynchronous processing of external integrations safely.
So the correct pattern is:
trigger ProductTrigger on Product__c (after insert, after update) {
for (Product__c prod : Trigger.new) {
ResizeImageAsync.resizeImage(prod.Id);
}
}
public class ResizeImageAsync {
@future(callout=true)
public static void resizeImage(Id productId) {
// HTTP callout to internal web app with JSON
}
}
❌ Why the Other Options Are Wrong:
B. A platform event that makes a callout to the web application
⇨ Platform events themselves do not make callouts.
⇨ You still need a triggered Apex handler, and event processing is async, but platform events are generally used for decoupled messaging—not ideal for this type of real-time image processing.
C. A flow that calls an @future method that allows callouts
⇨ Flows cannot directly call Apex @future methods.
⇨ Only invocable methods are supported in flows, and @future methods are not invocable.
⇨ This would throw an error at runtime.
D. A flow with an outbound message that contains a session ID
⇨ Outbound messages use the SOAP protocol, not JSON.
⇨ They are not flexible for formatting payloads like image data or JSON structures.
⇨ Sending a session ID over the network also has security risks.
Explanation:
Apex @future Methods — Salesforce Developer Docs
Universal Containers stores user preferences in a Hierarchy Custom Setting, User_Prefs_c, with a Checkbox field, Show_Help_c. Company-level defaults are stored at the organizational level, but may be overridden at the user level. If a user has not overridden preferences, then the defaults should be used. How should the Show_Help_c preference be retrieved for the current user?
A. Boolean show = User_Prefs__c.getValues(UserInfo.getUserId()).Show_Help__c;
B. Boolean show = User_Prefs__c.getInstance().Show_Help__c;
C. Boolean show = User_Prefs__c.Show_Help__c;
D. Boolean show = User_Prefs__c.getValues().Show_Help__c;
Explanation:
This question tests understanding of Hierarchy Custom Settings in Salesforce, which allow for:
➳ Org-wide defaults (set at the organization level), and
➳ User-specific overrides (set per user).
When using the method CustomSetting__c.getInstance(), Salesforce automatically checks for a user-level setting, and falls back to the organization-level default if none is found.
✅ Why Option B is correct:
Boolean show = User_Prefs__c.getInstance().Show_Help__c;
✔ This is the standard and recommended way to retrieve a value from a Hierarchy Custom Setting.
✔ It automatically resolves:
→ If user-level data exists → returns it.
→ Else → falls back to org-level default.
❌ Why the other options are incorrect:
A.
Boolean show = User_Prefs__c.getValues(UserInfo.getUserId()).Show_Help__c;
→ This only checks user-level values.
→ If no user-specific record exists, it returns null, not the org default — which violates the requirement.
C.
Boolean show = User_Prefs__c.Show_Help__c;
→ Invalid syntax — this assumes the setting is a static class or field, which it is not.
D.
Boolean show = User_Prefs__c.getValues().Show_Help__c;
→ This only returns org-level default — it ignores user-level overrides, so it's incorrect for this use case.
Reference:
Salesforce Docs – Custom Settings: Hierarchy and Usage
A company uses Dpportunities to track sales to their customers and their org has millions of Opportunities. They want to begin to track revenue over time through a related Revenue object. As part of their initial implementation, they want to perform a one-time seeding of their data by automatically creating and populating Revenue records for Opportunities, based on complex logic. They estimate that roughly 100,000 Opportunities will have Revenue records created and populated. What is the optimal way to automate this?
A. Use system, acheduladeb() to schedule a patakape.Scheduleable class.
B. Use system, enqueuJob (| to invoke a gueusable class.
C. Use Database. executeBatch () to invoke a Queueable class.
D. Use Database. =executeBatch() to invoke a Database. Batchable class.
Explanation:
The scenario describes a one-time data seeding process that involves:
⇨ Processing approximately 100,000 records,
⇨ Running complex logic,
⇨ Creating related records (Revenue),
⇨ Operating on a large dataset (millions of Opportunities).
This is a classic use case for a batch Apex job.
✅ Why Option D is correct:
Database.executeBatch(new MyBatchClass());
→ Database.Batchable is designed for processing large volumes of data efficiently and asynchronously.
→ It automatically handles chunking of data into batches (default: 200 records per batch).
→ It avoids governor limits (e.g., CPU time, SOQL rows, DML limits) by splitting work into manageable chunks.
→ Ideal for one-time or scheduled mass operations like data seeding, recalculation, or migration.
❌ Why the other options are incorrect:
A. System.schedule() with Schedulable class
→ Useful for recurring jobs (e.g., nightly runs).
→ Doesn't split large data efficiently — needs to call Batchable or Queueable from within.
→ Not needed for one-time seeding.
B. System.enqueueJob() with Queueable
→ Good for chaining jobs or async logic with smaller data sets.
→ Not optimal for large-scale (100k+) data, due to governor limits.
→ Not automatically chunked.
C. Database.executeBatch() with Queueable
→ Invalid. executeBatch() works with Database.Batchable, not Queueable classes.
🔗 Reference:
Apex Developer Guide – Batch Apex
A developer created an Opportunity trigger that updates the account rating when an
associated opportunity is considered high value. Current criteria for an opportunity
to be considered high value is an amount greater than or equal to $1,000,000. However,
this criteria value can change over time.
There is a new requirement to also display high value opportunities in a Lightning web
component.
Which two actions should the developer take to meet these business requirements, and
also prevent the business logic that obtains the high value opportunities from
being repeated in more than one place?
(Choose 2 answers)
A. Call the trigger from the Lightning web component.
B. Create a helper class that fetches the high value opportunities,
C. Leave the business logic code inside the trigger for efficiency.
D. Use custom metadata to hold the high value amount.
Explanation:
This scenario involves centralizing business logic (what qualifies as a "high value" opportunity) and making that logic easily reusable, configurable, and accessible in both Apex (trigger) and Lightning Web Components (LWC). The developer must avoid hardcoding and duplicate logic to reduce maintenance and support scalability.
✅ B. Create a helper class that fetches the high value opportunities
Using a shared Apex helper class to encapsulate the logic of determining which Opportunities are high value ensures code reusability and separation of concerns:
➳ The helper can contain one or more methods like isHighValue(Opportunity opp) or getHighValueOpportunities() that both the trigger and the LWC can call.
➳ This avoids duplicating logic across multiple locations (trigger, Apex controller, LWC).
➳ Changes to the business rule (e.g., the value threshold) only need to be made in the helper method.
🔹 Benefits:
➳ Promotes DRY principle (Don't Repeat Yourself).
➳ Makes unit testing easier.
➳ Improves readability and maintainability.
✅ D. Use custom metadata to hold the high value amount
Custom metadata allows business users or admins to modify configuration values without changing code or deploying to production. In this case:
➳ Store the threshold value (e.g., $1,000,000) in a Custom Metadata Type called Opportunity_Value_Criteria__mdt or similar.
➳ The helper class would read this value dynamically, so if the threshold changes in the future, there’s no need to redeploy code.
🔹 Benefits:
➳ Avoids hardcoding logic in the trigger or Apex class.
➳ Customizable through Setup UI.
➳ Supports dynamic logic that adapts to changing business needs.
❌ A. Call the trigger from the Lightning web component
Triggers are event-driven — they run automatically when records are inserted, updated, or deleted. They are not invokable from client-side code like LWCs.
→ LWCs must call Apex methods, not triggers.
→ Attempting to invoke a trigger directly violates the event-driven nature of Salesforce architecture.
❌ C. Leave the business logic code inside the trigger for efficiency
This violates the best practices of separating business logic from the trigger:
→ Keeping logic directly in the trigger leads to duplication (as the LWC would then need to reimplement it).
→ Makes the logic harder to maintain and test.
→ Not flexible for reuse in other contexts (e.g., batch jobs, LWC, REST API, etc.).
🔗 Reference:
Salesforce Developer Guide – Custom Metadata
Best Practices for Apex Triggers
LWC and Apex Integration
A company has reference data stored in multiple custom metadata records that represent default information and delete behavior for certain geographic regions.
When a contact is inserted, the default information should be set on the contact from the
custom metadata records based on the contact's address information.
Additionally, if a user attempts to delete a contact that belongs to a flagged region, the user
must get an error message.
Depending on company personnel resources, what are two ways to automate this?
(Choose 2 answers)
A. Remote action
B. Flow Builder
C. Apex trigger
D. Apex invocable method
Explanation:
✅ B. Flow Builder
Flow Builder is a powerful no-code tool that allows for complex logic execution and interaction with custom metadata. In this scenario:
✔ Before Save Flow (Record-Triggered Flow) can be used to set default values on insert.
✔ Custom Metadata Records can be queried using the Get Records element.
✔ Delete prevention can be implemented using a Before Delete Flow, which can use Decision elements and Fault elements to block deletion and return a message.
However, Flow’s ability to handle complex logic or nested conditions is limited, especially when it comes to handling cascading logic or comparing large sets of metadata records. So while viable, it’s best suited for simple to moderately complex use cases.
✅ C. Apex Trigger
Apex triggers are highly flexible and support complex conditional logic. In this case:
✔ A before insert trigger can be used to read custom metadata and populate default values on the Contact record.
✔ A before delete trigger can check the contact’s address against metadata rules and use addError() to block deletion.
✔ Apex provides access to Custom Metadata via SOQL (though in read-only fashion), which allows more advanced logic than Flow can easily support.
This is the most robust and scalable solution, especially if the logic is expected to evolve or becomes more sophisticated.
❌ A. Remote Action
@RemoteAction methods are used to expose Apex to Visualforce pages via JavaScript. This technology is outdated for Lightning experiences and LWCs, and not suitable for record-level automation like validation or default-setting during data creation or deletion. It also doesn’t fire automatically — it's invoked manually via the front end.
❌ D. Apex Invocable Method
An InvocableMethod is designed to be called from Flows or Processes, not on its own. On its own, it can’t listen for record insert or delete events.
While you could write an invocable Apex method to encapsulate business logic, you'd still need Flow to call it, and it’s not capable of triggering on data events like a trigger does.
Thus, it’s not a complete solution by itself for automation.
🔗 References:
Custom Metadata Overview – Salesforce
Apex Triggers Developer Guide
Flow Builder Use Cases
Which code snippet processes records in the most memory efficient manner, avoiding governor limits such as "Apex heap size too large"?

A. Option A
B. Option B
C. Option C
D. Option D
Explanation:
Option A:
This approach queries all Opportunity records into a single List in memory at once. If there are many records (e.g., tens of thousands), this can easily exceed the heap size limit, leading to a "Apex heap size too large" error. This is not memory-efficient for large datasets.
Option B:
This uses a SOQL query directly in a for loop, which implicitly processes records in batches of 200 using Salesforce's iterative SOQL feature. This approach is more memory-efficient because it doesn't load all records into memory at once, staying within the governor limit of 200 records per iteration. This is a recommended practice for processing large datasets.
Option C:
Similar to Option A, this queries all Opportunity records into a Map in memory at once. While a Map might use slightly different memory structures, the total heap usage will still depend on the number of records. For large datasets, this will also risk exceeding the heap size limit, making it inefficient.
Option D:
This uses Database.query() to execute a dynamic SOQL query, but it still loads all records into a List in memory at once, just like Option A. The dynamic nature doesn't change the memory footprint, so it suffers from the same inefficiency and heap size risk as Option A.
Correct Answer: Option B
Explanation:
Option B is the most memory-efficient because it leverages Salesforce's iterative SOQL feature. When a SOQL query is used directly in a for loop (e.g., for (Opportunity opp : [SOQL])), Salesforce automatically processes the records in batches of 200, iterating over the result set without loading all records into memory simultaneously. This approach helps avoid the "Apex heap size too large" error by managing memory usage per iteration, making it suitable for handling large datasets within governor limits.
Key Considerations:
The heap size limit is enforced per execution context, and loading all records at once (as in Options A, C, and D) can quickly exceed this limit with large datasets.
Iterative SOQL (Option B) is a best practice recommended by Salesforce for bulk processing, as outlined in the Apex Developer Guide.
Reference:
Salesforce Apex Developer Guide: "SOQL and SOSL Queries" - Section on Iterative SOQL (available on Salesforce Help: Types of Procedural Loops
Given the following containment hierarchy:

A. Option A
B. Option B
C. Option C
D. Option D
Explanation:
📘 Explanation:
CustomEvent('passthrough', {...}): creates a custom event named 'passthrough'.
{ detail: this.passthrough }: sends the value of passthrough in the detail payload (required for passing data).
this.dispatchEvent(cEvent): dispatches the event to the DOM so that the parent component can catch it using an event handler like
❌ Why Other Options Are Incorrect:
A: Incorrect syntax (customEvent should be CustomEvent) — JavaScript is case-sensitive.
B: Doesn't pass any detail, so parent won’t receive the passthrough value.
D: passthrough is passed as a variable without quotes, causing a ReferenceError unless a variable named passthrough exists (but not passing it correctly in detail either).
Reference:
Salesforce Developer Guide - Create and Dispatch Events
| Page 2 out of 21 Pages |
| 1234567 |
| Salesforce-Platform-Developer-II Practice Test Home |
Our new timed 2026 Salesforce-Platform-Developer-II practice test mirrors the exact format, number of questions, and time limit of the official exam.
The #1 challenge isn't just knowing the material; it's managing the clock. Our new simulation builds your speed and stamina.
You've studied the concepts. You've learned the material. But are you truly prepared for the pressure of the real Salesforce Certified Platform Developer II (SP25) exam?
We've launched a brand-new, timed Salesforce-Platform-Developer-II practice exam that perfectly mirrors the official exam:
✅ Same Number of Questions
✅ Same Time Limit
✅ Same Exam Feel
✅ Unique Exam Every Time
This isn't just another Salesforce-Platform-Developer-II practice questions bank. It's your ultimate preparation engine.
Enroll now and gain the unbeatable advantage of:
Copyright © - All Rights Reserved