Total 202 Questions
Last Updated On : 8-Jul-2026

A company accepts orders for customers in their enterprise resource planning (ERP)
system that must be integrated into Salesforce as order_ c records with a lookup field to
Account. The Account object has an external ID field, ENF_Customer_ID_c.
What should the Integration use to create new Oder_c records that will automatically be
related to the correct Account?

A. Option A
B. Option B
C. Option C
D. Option D
Explanation:
To integrate order data from an enterprise resource planning (ERP) system into Salesforce as Order__c records with a lookup field to the Account object, the integration must efficiently relate the new records to the correct Account using the external ID field ERP_Customer_ID__c. The solution should minimize manual mapping, ensure data integrity, and leverage Salesforce's data manipulation language (DML) operations that support external ID-based relationships. Let's evaluate each option based on these requirements.
Correct Answer: D. Upsert on the Account and specify the ERP_Customer_ID__c for the relationship
Option D, "Upsert on the Account and specify the ERP_Customer_ID__c for the relationship," is the optimal choice. The upsert operation in Salesforce allows the integration to create or update Order__c records based on an external ID. By specifying ERP_Customer_ID__c in the lookup relationship field of the Order__c record, Salesforce automatically matches it to the corresponding Account record using the external ID, establishing the relationship without requiring the Account ID. This method is efficient, supports bulk operations, and aligns with integration best practices, making it ideal for the Platform Developer II exam context.
Incorrect Answer:
Option A: Upsert on the Order__c object and specify the ERP_Customer_ID__c for the Account relationship
Option A suggests performing an upsert on the Order__c object and using ERP_Customer_ID__c for the Account relationship. However, upsert on Order__c would require an external ID on the Order__c object itself, not the Account object, to match existing records. Using ERP_Customer_ID__c (an Account external ID) in this context is invalid for the upsert operation, as the lookup relationship cannot directly resolve the Account ID this way. This approach would fail or require additional logic, making it unsuitable.
Option B: Insert on the Order__c object followed by an update on the related Account object
Option B proposes inserting Order__c records and then updating the related Account object. This two-step process is inefficient and impractical. Initially, the Order__c insert would lack the correct Account ID in the lookup field, requiring a separate query or update to establish the relationship using ERP_Customer_ID__c. This approach increases complexity, risks data inconsistencies, and exceeds the number of DML operations, violating governor limits in bulk scenarios. It is not a streamlined solution for this integration.
Option C: Merge on the Order__c object and specify the ERP_Customer_ID__c for the Account relationship
Option C suggests using a merge operation on Order__c with ERP_Customer_ID__c for the Account relationship. However, the merge operation in Salesforce is used to combine duplicate records within the same object (e.g., merging duplicate Accounts), not to establish relationships or create new records with lookups. Applying merge to Order__c with an Account external ID is invalid and does not support the creation of new Order__c records related to Account. This option is incorrect for the given requirement.
Reference:
Salesforce Apex Developer Guide: "Upsert" - Section on External ID Relationships.
Universal Containers analyzes a Lightning web component and its Apex controller
class that retrieves a list of contacts associated with an account. The code snippets
are as follows: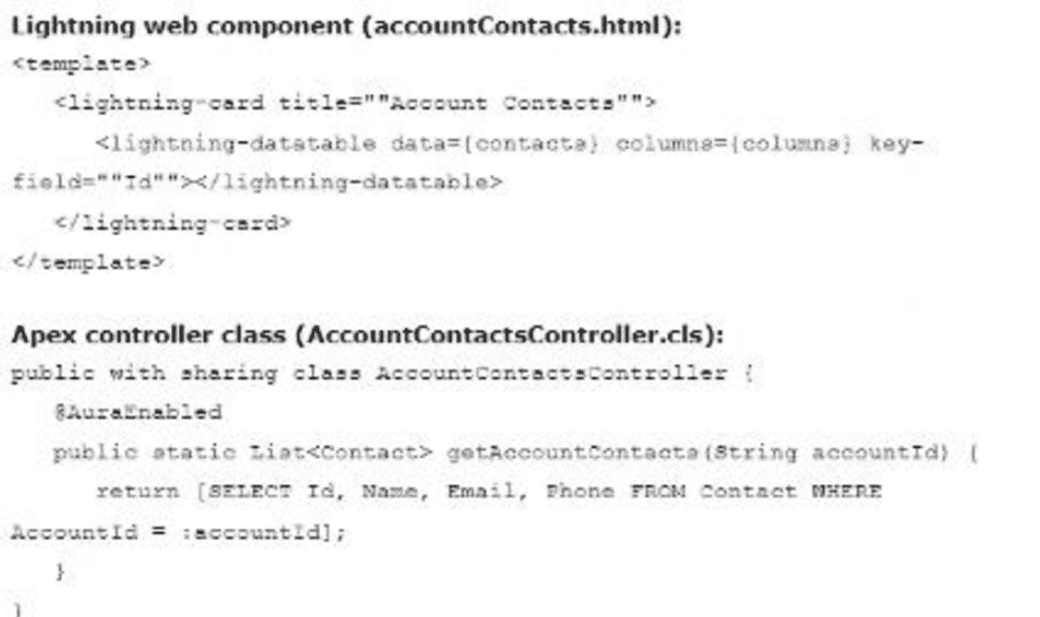
Based on the code snippets, what change should be made to display the contacts’ mailing
addresses in the Lightning web component?
A. Add a new method in the Apex controller class to retneve the mailing addresses separately and modify the Lightning web component to invoke this method.
B. Extend the lightning-datatable component in the Lightning web component to include a column for the MailingAddress field.
C. Modify the SOQL guery in the getAccountContacts method to include the MailingAddress field.
D. Modify the SOQL query in the getAccountContacts method to include the MailingAddress field and update the columns attribute in javascript file to add Mailing address fields.
Explanation:
To display the contacts' mailing addresses in the Lightning web component, the developer needs to ensure that the MailingAddress field data is retrieved from Salesforce and properly rendered in the lightning-datatable. The current code retrieves Id, Name, Email, and Phone fields for Contacts via the Apex controller method getAccountContacts, but it does not include MailingAddress. The solution must update the data retrieval and configure the datatable to display this additional field effectively.
Correct Answer: D. Modify the SOQL query in the getAccountContacts method to include the MailingAddress field and update the columns attribute in JavaScript file to add Mailing address fields
Option D is the correct approach. The MailingAddress field must be added to the SOQL query in the getAccountContacts method (e.g., SELECT Id, Name, Email, Phone, MailingAddress FROM Contact WHERE AccountId = :accountId) to retrieve the data from Salesforce. Additionally, the columns attribute in the JavaScript file of the Lightning web component must be updated to include a new column definition for MailingAddress (e.g., { label: 'Mailing Address', fieldName: 'MailingAddress' }). This ensures the datatable displays the mailing addresses alongside other fields, aligning with LWC best practices and the Platform Developer II exam requirements for data presentation.
Incorrect Answer:
Option A: Add a new method in the Apex controller class to retrieve the mailing addresses separately and modify the Lightning web component to invoke this method
Option A suggests adding a separate Apex method to retrieve MailingAddress and updating the component to call it. While technically possible, this approach is inefficient, as it requires an additional server call, increasing latency and complexity. The existing getAccountContacts method can be modified to include MailingAddress in a single query, avoiding the need for a new method. This overcomplicates the solution and is unnecessary when a single SOQL update suffices, making it less optimal.
Option B: Extend the lightning-datatable component in the Lightning web component to include a column for the MailingAddress field
Option B proposes extending the lightning-datatable to include a MailingAddress column. However, lightning-datatable is a base component that cannot be extended directly; its behavior is configured via the columns and data attributes. Without updating the SOQL query to include MailingAddress, the data won't be available, and adding a column without data will result in errors or empty cells. This approach lacks the necessary backend change, rendering it incomplete and incorrect.
Option C: Modify the SOQL query in the getAccountContacts method to include the MailingAddress field
Option C correctly identifies the need to modify the SOQL query to include MailingAddress (e.g., SELECT Id, Name, Email, Phone, MailingAddress FROM Contact WHERE AccountId = :accountId), which retrieves the data. However, it does not address the frontend requirement to display this field in the lightning-datatable. The columns attribute in the JavaScript file must also be updated to define a MailingAddress column. Without this step, the retrieved data remains unused, making this option partially correct but insufficient for the full solution.
Reference:
Salesforce LWC Developer Guide: "lightning-datatable".
Salesforce Apex Developer Guide: "SOQL Queries".
Universal Containers develops a Salesforce application that requires frequent interaction
with an external REST API.
To avoid duplicating code and improve maintainability, how should they implement the APL
integration for code reuse?
A. Use a separate Apex class for each API endpoint to encapsulate the integration logic,
B. Include the API integration code directly in each Apex class that requires it.
C. Create a reusable Apex class for the AFL integration and invoke it from the relevant Apex classes.
D. Store the APT integration code as a static resource and reference it in each Apex class.
Explanation:
To implement an external REST API integration for a Salesforce application that requires frequent interaction, while avoiding code duplication and improving maintainability, the solution must centralize the integration logic in a reusable manner. The approach should align with Apex best practices, support scalability, and allow multiple classes to leverage the integration without redundant code. Let's evaluate each option based on these principles.
Correct Answer: C. Create a reusable Apex class for the API integration and invoke it from the relevant Apex classes
Option C is the optimal solution. By creating a reusable Apex class (e.g., ApiIntegrationService) to handle the REST API calls, including methods for authentication, request construction, and response parsing, Universal Containers can centralize the integration logic. Other Apex classes can then invoke this class's methods as needed, reducing duplication and ensuring consistent behavior. This approach enhances maintainability, as updates to the API logic are made in one place, and it aligns with object-oriented design principles. For the Platform Developer II exam, this demonstrates proficiency in reusable code design.
Incorrect Answer:
Option A: Use a separate Apex class for each API endpoint to encapsulate the integration logic
Option A suggests creating a separate Apex class for each API endpoint, which encapsulates the integration logic but leads to code duplication if common functionality (e.g., authentication, error handling) is repeated across classes. This approach increases maintenance overhead, as changes to the API structure require updates to multiple classes. While it provides encapsulation, it lacks the reusability needed for frequent interactions, making it less efficient and not ideal for a scalable Salesforce application.
Option B: Include the API integration code directly in each Apex class that requires it
Option B involves embedding the API integration code directly into each Apex class that needs it. This results in significant code duplication, as the same REST call logic (e.g., HTTP requests, error handling) is replicated across classes. Such an approach complicates maintenance, as any API change requires updating every class, increasing the risk of errors and violating DRY (Don't Repeat Yourself) principles. This is highly inefficient and unsuitable for a maintainable Salesforce solution.
Option D: Store the API integration code as a static resource and reference it in each Apex class
Option D proposes storing the API integration code as a static resource (e.g., JavaScript or a script) and referencing it in Apex classes. However, Apex cannot directly execute JavaScript from static resources, and this approach is impractical for server-side logic. Static resources are better suited for client-side code or assets, not for reusable Apex logic. This method would require complex workarounds (e.g., Visualforce bridges), making it inefficient and incompatible with the requirement for Apex-based integration.
Reference:
Salesforce Apex Developer Guide: "Calling External Objects Using REST API".
An Aura component has a section that displays some information about an Account and it works well on the desktop, but users have to scroll horizontally to see the description field output on their mobile devices and tablets.

A. Option A
B. Option B
C. Option C
D. Option D
Explanation:
The Aura component uses a lightning:layout to display Account information, including Name and Description, within lightning:layoutItem components. The current setup with multipleRows="false" and fixed size="12" for each item causes the layout to span a single row, which works on desktops but requires horizontal scrolling on mobile and tablet devices due to limited screen width. To make the component responsive, the layout must adapt to smaller screen sizes by adjusting the size attribute based on device type, ensuring content fits without scrolling.
Correct Answer: Option D
Option D is the correct solution. By setting multipleRows="false" and using smallDeviceSize="12" and largeDeviceSize="6" on each lightning:layoutItem, the layout adjusts dynamically. On mobile and tablet devices (classified as small devices), each item takes the full 12-column width, stacking them vertically to avoid horizontal scrolling. On larger devices (e.g., desktops), each item uses 6 columns, fitting both Name and Description side by side. This responsive design leverages Salesforce's built-in breakpoints, ensuring usability across devices, which is critical for the Platform Developer II exam.
Incorrect Answer:
Option A:
Option A uses a fixed size="12" for the Name item and size="6" for the Description item with multipleRows="false". This configuration forces both items into a single row, but the total size (12 + 6 = 18) exceeds the 12-column grid, causing overflow and horizontal scrolling on smaller screens. The lack of device-specific sizing (smallDeviceSize or largeDeviceSize) prevents responsiveness, making it ineffective for mobile and tablet devices, thus unsuitable for the requirement.
Option B:
Option B sets smallDeviceSize="12" for the Name item but leaves the Description item without a specified size, defaulting to the parent layout size. With multipleRows="false", both items are forced into one row, and the unspecified size for Description can lead to inconsistent rendering, potentially causing overflow or truncation on small devices. This approach lacks a comprehensive device-specific strategy, failing to ensure the layout is fully responsive for mobile and tablet users.
Option C:
Option C uses multipleRows="true" with size="12" and largeDeviceSize="6". On small devices, size="12" stacks the items vertically, which is responsive, but multipleRows="true" can lead to unpredictable wrapping behavior depending on content. On large devices, largeDeviceSize="6" fits both items side by side, but the initial size="12" overrides responsiveness on smaller screens if not consistently applied. This hybrid approach lacks clarity and precision, making it less reliable than Option D for consistent mobile and tablet responsiveness.
Reference:
Salesforce Aura Components Developer Guide: "lightning:layout".
Universal Containers wants to notify an external system, in the event that an unhandled exception occurs, by publishing a custom event using Apex. What is the appropriate publish/subscribe logic to meet this requirement?
A. Publish the error event using the Eventrus.publish() method and have the external system subscribe to the event using CometD.
B. Publish the error event using the addError () method and write a trigger to subscribe to the event and notify the external system.
C. Have the external system subscribe to the event channel. No publishing is necessary.
D. Publish the error event using the addError () method and have the external system subscribe to the event using CometD.
Explanation:
To notify an external system when an unhandled exception occurs by publishing a custom event using Apex, the solution must leverage Salesforce's publish/subscribe model, which supports real-time event messaging. This requires publishing the event from Apex and enabling the external system to subscribe to it, typically using a mechanism like CometD, a popular library for real-time communication. The approach should align with Salesforce's event-driven architecture and ensure the external system can react to the exception.
Correct Answer: A. Publish the error event using the Eventbus.publish() method and have the external system subscribe to the event using CometD
Option A is the correct approach. The Eventbus.publish() method in Apex is designed to publish custom Platform Events, which can carry details of an unhandled exception (e.g., error message, stack trace) as a payload. The external system can subscribe to this event channel using CometD, a JavaScript library that supports the Bayeux protocol for real-time updates over a long-polling or WebSocket connection. This setup enables asynchronous notification, adheres to Salesforce's event-driven model, and is ideal for integrating with external systems, making it suitable for the Platform Developer II exam context.
Incorrect Answer:
Option B: Publish the error event using the addError() method and write a trigger to subscribe to the event and notify the external system
Option B is incorrect because the addError() method is used to display error messages to users within Salesforce (e.g., on a record or page) and does not publish events for external consumption. Writing a trigger to subscribe to an error is not feasible, as triggers react to DML operations, not error events, and cannot directly notify an external system. This approach misunderstands the publish/subscribe model and lacks a mechanism for external integration, rendering it invalid.
Option C: Have the external system subscribe to the event channel. No publishing is necessary
Option C suggests that the external system can subscribe to an event channel without any publishing from Apex. However, the publish/subscribe model requires an event to be published (e.g., via Eventbus.publish()) before a subscriber can receive it. Without Apex publishing the unhandled exception event, the external system has nothing to subscribe to, making this approach ineffective. This option overlooks the necessity of event generation, which is critical for the requirement.
Option D: Publish the error event using the addError() method and have the external system subscribe to the event using CometD
Option D is incorrect because addError() does not publish events; it only sets an error state within Salesforce for user feedback. Even with CometD, the external system cannot subscribe to an event that isn’t published via a mechanism like Platform Events. This approach confuses error handling with event publishing, and without a valid publish step (e.g., Eventbus.publish()), the external system cannot receive notifications. This makes it an unsuitable solution for the given requirement.
Reference:
Platform Events Developer Guide
Salesforce CometD Documentation
Universal Containers is using a custom Salesforce application to manage customer support cases. The support team needs to collaborate with external partners to resolve certain cases. However, they want to control the visibility and access to the cases shared with the external partners. Which Salesforce feature can help achieve this requirement?
A. Role hierarchy
B. Criteria-based sharing rules
C. Apex managed sharing
D. Sharing sets
Explanation:
To manage customer support cases in a custom Salesforce application where the support team collaborates with external partners while controlling visibility and access, the solution must allow selective sharing with external users (e.g., partners) based on specific conditions. The feature should integrate with Salesforce's security model, support external access (e.g., via Community or Partner portals), and provide granular control over case sharing.
Correct Answer: C. Apex managed sharing
Option C, Apex managed sharing, is the appropriate feature. Apex managed sharing allows developers to programmatically share records, such as cases, with specific users or groups, including external partners, using custom logic. This is ideal for controlling visibility and access based on complex criteria (e.g., case type, priority, or partner role) that standard sharing rules might not handle. By writing Apex triggers or classes, Universal Containers can dynamically grant access to external partners via sharing rules, ensuring security and collaboration. This aligns with the Platform Developer II exam's focus on advanced security customization.
Incorrect Answer:
Option A: Role hierarchy
Option A, Role hierarchy, defines access based on an organization's internal user roles (e.g., managers vs. subordinates) and automatically grants access to records owned by users below in the hierarchy. However, it is designed for internal users and does not natively support sharing with external partners, such as those in a Community or Partner portal. While it can influence visibility, it lacks the flexibility to control access for external collaborators, making it unsuitable for this requirement.
Option B: Criteria-based sharing rules
Option B, Criteria-based sharing rules, allows sharing records with users or groups based on field values (e.g., case status or priority). While useful for internal sharing, it is limited to predefined criteria and does not directly support sharing with external partners unless they are part of a Community with specific profiles or roles. This feature lacks the dynamic, programmatic control needed to manage external partner access on a case-by-case basis, rendering it less effective here.
Option D: Sharing sets
Option D, Sharing sets, are used in Communities to grant access to records (e.g., cases) for Community users based on their profile and a common field (e.g., Account ID). While this can share cases with external partners in a Community, it provides broad access based on predefined rules rather than granular control per case or partner. It is less flexible for managing visibility and access dynamically, making it less suitable than Apex managed sharing for Universal Containers' specific collaboration needs.
Reference:
Salesforce Security and Sharing Guide: "Apex Managed Sharing".
Consider the following code snippet:
The Apex method is executed in an environment with a large data volume count for
Accounts, and the query is performing poorly.
Which technique should the developer implement to ensure the query performs optimally,
while preserving the entire result set?
A. Create a formula field to combine the createdDate and RecordType value, then filter based on the formula.
B. Break down the query into two individual queries and join the two result sets.
C. Annotate the method with the @Future annotation
D. Use the Database queryLocator method to retrieve the accounts.
Explanation:
The Apex method getAccounts queries Accounts based on CreatedDate or RecordTypeId, operating in an environment with a large data volume where the query performs poorly. To optimize performance while preserving the entire result set, the solution must address query efficiency, potentially leveraging batch processing or indexing, without altering the logical outcome. The technique should align with Salesforce best practices for handling large datasets and respect governor limits.
Correct Answer: D. Use the Database.queryLocator method to retrieve the accounts
Option D is the correct technique. The Database.queryLocator method, used with Database.Batchable or Database.getQueryLocator(), is designed for processing large datasets by enabling batch execution. It retrieves records in chunks (up to 50 million records), optimizing query performance by avoiding heap size limits and reducing the load on the system. This preserves the entire result set (Accounts where CreatedDate = thisDate or RecordTypeId = goldenRT) while improving efficiency in a high-volume environment. This approach is ideal for the Platform Developer II exam, focusing on scalable query handling.
Incorrect Answer:
Option A: Create a formula field to combine the createdDate and RecordType value, then filter based on the formula
Option A suggests creating a formula field to combine CreatedDate and RecordTypeId for filtering. While a formula could concatenate these values, it would not inherently improve query performance, as the underlying SOQL still scans the same large dataset. Formula fields are not indexed by default, and this approach adds maintenance overhead without addressing the root performance issue. It also risks complicating the logic and does not guarantee preservation of the full result set, making it suboptimal.
Option B: Break down the query into two individual queries and join the two result sets
Option B proposes splitting the query into two (e.g., one for CreatedDate and one for RecordTypeId) and joining the results. However, Apex does not support joining query results directly, and this would require manual list manipulation, increasing code complexity and memory usage. This approach does not inherently optimize the query against a large dataset and could exceed governor limits (e.g., 10,000 DML rows) if not batched, failing to address the performance issue effectively.
Option C: Annotate the method with the @Future annotation
Option C suggests using the @Future annotation to run the method asynchronously. While this moves the execution to a separate thread, avoiding immediate governor limit conflicts, it does not optimize the query itself. The same poorly performing SOQL would still execute, potentially hitting heap size or CPU time limits in the future context. It also does not handle large result sets efficiently without batching, making it an incomplete solution for preserving the entire result set while improving performance.
Reference:
Salesforce Apex Developer Guide: "Database.QueryLocator".
Salesforce Governor Limits
A company has a native iOS order placement app that needs to connect to Salesforce to retrieve consolidated information from many different objects in a JSON format. Which is the optimal method to implement this in Salesforce?
A. Apex REST web service
B. Apex SOAP web service
C. Apex SOAP callout
D. Apex REST callout
Explanation:
When a native iOS app needs to connect to Salesforce and retrieve data from multiple objects in JSON format, the best approach is to expose an Apex REST web service.
Why Apex REST is optimal:
✅ JSON-native: REST APIs natively return data in JSON, which is ideal for mobile platforms like iOS that handle JSON easily.
✅ Customizable Response: Apex REST methods allow you to query multiple objects, consolidate data, and return a custom JSON structure, all in one response — perfect for mobile app consumption.
✅ Stateless & Lightweight: REST APIs are lightweight and stateless, which makes them ideal for mobile devices with limited bandwidth and resources.
✅ OAuth-Compatible: REST services in Salesforce work seamlessly with OAuth 2.0, allowing secure access from external mobile apps.
❌ Incorrect Answers:
B) Apex SOAP web service
While Apex SOAP web services can expose Salesforce data, SOAP is XML-based, which is heavier and less mobile-friendly than JSON. iOS apps typically use JSON over REST for better performance and easier parsing. SOAP also requires WSDLs and extra configuration, which introduces unnecessary complexity for mobile integration.
C) Apex SOAP callout
This refers to Salesforce making a SOAP call to an external system, not receiving a call from an iOS app. This doesn’t apply to the question — the iOS app is the client, and Salesforce is the provider. So this direction of integration is incorrect.
D) Apex REST callout
Again, a REST callout is when Salesforce calls out to another external system via HTTP REST. In this scenario, Salesforce is not initiating the call — the iOS app is. So, REST callout is irrelevant here.
🔗 Reference:
Salesforce Developer Guide – Apex REST
Trailhead – Expose Data with Apex REST
Mobile SDK Guide – iOS to Salesforce
A developer needs to implement a system audit feature that allows users, assigned to a
custom profile named "Auditors", to perform searches against the historical records in the
Account object. The developer must ensure the search is able to return history records that
are between 6 and 12 months old.
Given the code below, which select statement should be inserted below as a valid way to
retrieve the Account History records ranging from 6 to 12 months old?
A. Option A
B. Option B
C. Option C
D. Option D
Explanation:
The developer needs to implement a system audit feature to allow users with the "Auditors" profile to search Account history records between 6 and 12 months old. The code snippet defines variables initialDate and endDate using System.today().addMonths(-12) and System.today().addMonths(-6), respectively, representing the date range. The SELECT statement must query the AccountHistory object, which tracks field changes, and filter records where CreatedDate falls within this range (initialDate to endDate). The solution should ensure accurate date filtering and align with Salesforce SOQL syntax.
Correct Answer: Option C
Option C is the correct SELECT statement. It queries AccountId, CreatedDate, Field, NewValue, and OldValue from the AccountHistory object, which stores historical changes to Account fields. The WHERE clause uses CreatedDate >= :initialDate AND CreatedDate <= :endDate to filter records between 6 and 12 months old, leveraging the bind variables initialDate (12 months ago) and endDate (6 months ago) defined earlier. This ensures the query returns the exact range required, adhering to SOQL best practices and supporting the audit feature for the "Auditors" profile.
Incorrect Answer:
Option A:
Option A uses CreatedDate >= :initialDate AND CreatedDate < :endDate, which includes records from 12 months ago up to, but not including, 6 months ago. This excludes records exactly at the endDate (6 months ago), potentially missing relevant history data. For an inclusive range of 6 to 12 months, the query should use <= :endDate to capture all records up to and including 6 months ago. This subtle exclusion makes Option A incorrect for the full requirement.
Option B:
Option B reverses the date range with CreatedDate >= :endDate AND CreatedDate < :initialDate, which would filter records from 6 months ago to before 12 months ago. This inverts the intended range (6 to 12 months old), returning an empty or incorrect result set since endDate (6 months ago) is greater than initialDate (12 months ago). This logical error fails to meet the requirement of retrieving history records between 6 and 12 months old.
Option D:
Option D uses CreatedDate >= :initialDate AND CreatedDate > :endDate, which attempts to filter records from 12 months ago where CreatedDate is also after 6 months ago. This creates a contradictory condition, as no date can be both >= 12 months ago and > 6 months ago, resulting in an empty result set. The incorrect use of > instead of <= for endDate invalidates the query, making it unsuitable for the 6 to 12-month range requirement.
Reference:
Salesforce Object Query Language (SOQL)
Salesforce Data Model: "AccountHistory Object".
An org records customer order information in a custom object, ordar__c, that has fields for the shipping address. A developer is tasked with adding code to calculate shipping charges on an order, based on a flat percentage rate associated with the region of the shipping address. What should the developer use to store the rates by region, so that when the changes are deployed to production no additional steps are needed for the calculation to work?
A. Custom hierarchy setting
B. Custom metadata type
C. Custom list setting
D. Custom object
Explanation:
The most appropriate choice is Custom Metadata Type, because it allows you to store configuration data, like shipping rates by region, in metadata, and it is:
✅ Deployed with change sets, unlocked packages, or metadata API — no post-deployment steps like data entry required.
✅ Accessible in Apex without querying (like CustomMetadataType__mdt.getAll()), which improves performance.
✅ Non-editable by end users in production without permission (unlike Custom Settings), ensuring stability.
✅ Ideal for application configuration values like shipping percentages, tax rates, thresholds, etc.
In this use case:
You’d create a Custom Metadata Type like Shipping_Rate__mdt
It would have fields like Region__c and Rate__c
You could query or access it in Apex to calculate charges
Example Apex usage:
Map
Decimal rate = rates.get(order.Region__c).Rate__c;
order.Shipping_Charge__c = order.Amount__c * rate;
This ensures that shipping logic works immediately after deployment, with no manual steps required in the production org.
❌ Incorrect Answers:
A) Custom hierarchy setting
Hierarchy settings are meant for user- or profile-specific configuration — not for general data like region-based shipping rates. They support per-user overrides, which is unnecessary and confusing for a flat shipping percentage by region. Also, their data must be manually created or updated in production after deployment unless you use a script.
C) Custom list setting
Custom list settings are similar to custom objects but are data, not metadata, meaning they require post-deployment data population. You cannot deploy data in list settings via metadata tools alone — you’d need to run a script or manually enter the data in production, violating the requirement.
D) Custom object
Custom objects are used to store business data, not configuration. Like list settings, the data in custom objects must be manually populated or scripted post-deployment, which contradicts the requirement that the calculation works immediately after deployment. This introduces operational overhead and risk.
🔗 Reference:
Salesforce – Custom Metadata Types Overview
Trailhead – Configure Your App Using Custom Metadata Types
| Page 4 out of 21 Pages |
| 1234567 |
| Salesforce-Platform-Developer-II Practice Test Home |
Our new timed 2026 Salesforce-Platform-Developer-II practice test mirrors the exact format, number of questions, and time limit of the official exam.
The #1 challenge isn't just knowing the material; it's managing the clock. Our new simulation builds your speed and stamina.
You've studied the concepts. You've learned the material. But are you truly prepared for the pressure of the real Salesforce Certified Platform Developer II (SP25) exam?
We've launched a brand-new, timed Salesforce-Platform-Developer-II practice exam that perfectly mirrors the official exam:
✅ Same Number of Questions
✅ Same Time Limit
✅ Same Exam Feel
✅ Unique Exam Every Time
This isn't just another Salesforce-Platform-Developer-II practice questions bank. It's your ultimate preparation engine.
Enroll now and gain the unbeatable advantage of:
Copyright © - All Rights Reserved