Total 202 Questions
Last Updated On : 8-Jul-2026

Consider the below trigger intended to assign the Account to the manager of the Account's region:

A. Option A
B. Option B
C. Option C
D. Option D
Explanation:
❌ Option A: Add if (!accountList.isEmpty()) before updating accountList
Adding a condition like if (!accountList.isEmpty()) before updating accountList is a precautionary step to ensure the list contains records before processing. This practice helps avoid null pointer exceptions or unnecessary operations if the list were unexpectedly empty. In the context of this trigger, accountList is initialized as new List
✅ Option B: Move the Region__c query outside the loop
Moving the Region__c query outside the loop is a crucial best practice to enhance performance and scalability. Currently, the trigger queries Region__c for each Account in trigger.new using anAccount.Region__Name__c, which can lead to multiple SOQL queries and potentially exceed the 100 SOQL query governor limit if more than 100 Accounts are processed. By collecting all unique Region__Name__c values into a Set
❌ Option C: Use a Map to cache the results of the Region__c query by Id
Using a Map to cache the results of the Region__c query by Id is an optimization technique to improve performance by storing query results for quick access. This approach is particularly useful when the same data might be queried multiple times or when relating records by a unique identifier like Id. However, in this trigger, the query is based on Name (from anAccount.Region__Name__c) rather than Id, so caching by Id isn’t directly applicable unless the relationship changes to a lookup field. A Map
✅ Option D: Remove the last line that updates accountList because it is not needed
Removing the last line update accountList; is essential because it’s unnecessary in a before trigger context. In before triggers, any modifications to trigger.new—such as setting anAccount.OwnerId—are automatically persisted to the database when the trigger completes, eliminating the need for an explicit DML operation. Keeping this line can lead to runtime errors, such as recursion or constraint violations, and consumes governor limits (e.g., 150 DML statements), though it’s unlikely to hit the limit here. This change simplifies the code, reduces overhead, and aligns with best practices for leveraging the implicit save behavior of before triggers. If the trigger were an after trigger, an update would be required, but given the current design, removing it is a clear improvement, making it a selected option.
Why Options B and D?
Option B addresses the critical performance issue of querying inside a loop, bulkifying the trigger to handle large datasets within governor limits, a core Salesforce best practice.
Option D eliminates redundant DML, simplifying the code and preventing potential errors, aligning with efficient trigger design.
Together, these changes optimize performance and correctness, ensuring the trigger is robust for production use.
References:
Trigger Best Practices
Governor Limits
Recently, users notice that fields that were recently added for one department suddenly
disappear without warning.
Which two statements are true regarding these issues and resolution?
(Choose 2 answers)
A. A sandbox should be created to use as a unified testing environment instead of deploying Change Sets directly to production.
B. Page Layouts should never be deployed via Change Sets, as this causes Field-Level Security to be reset and fields to disappear.
C. The administrators are deploying their own Change Sets over each other, thus replacing entire Page Layouts in production.
D. The administrators are deploying their own Change Sets, thus deleting each other's fields from the objects in production.
Explanation:
✅ A. A sandbox should be created to use as a unified testing environment instead of deploying Change Sets directly to production.
True.
Deploying directly to production without consistent testing can result in unintentional overwrites of components like page layouts.
A centralized UAT sandbox allows admins/developers to merge and test changes together before pushing to production.
This helps prevent conflicts between separate Change Sets that touch the same metadata.
✅ C. The administrators are deploying their own Change Sets over each other, thus replacing entire Page Layouts in production.
True.
When a Page Layout is included in a Change Set, it is deployed as a whole — not merged.
If two admins modify the same page layout in different ways, and each deploys it separately, the last one deployed overwrites the previous.
This can lead to fields disappearing from the layout if the second admin didn’t include them in their version.
❌ B. Page Layouts should never be deployed via Change Sets, as this causes Field-Level Security to be reset and fields to disappear.
False.
Page Layouts can be safely deployed via Change Sets, and doing so does not reset Field-Level Security (FLS).
FLS is controlled separately (through profiles and permission sets), and Change Sets allow you to include FLS for fields explicitly if needed.
Fields "disappearing" from the layout is due to layout overwrites, not FLS resets.
❌ D. The administrators are deploying their own Change Sets, thus deleting each other's fields from the objects in production.
False.
Change Sets cannot delete custom fields from objects.
They only add or modify metadata; deletion must be done manually or through destructive changes via Metadata API, not through Change Sets.
The fields still exist in the object but are likely missing from the layout, leading to the perception of being "deleted."
📚 Best Practices:
➡️ Use source control and sandbox collaboration to manage metadata.
➡️ Avoid parallel Change Set deployments that modify the same metadata.
➡️ Consider using second-generation packaging or DevOps tools (e.g., Copado, Gearset) for coordinated releases.
Consider the controller code below that is called from an Aura component and
returns data wrapped in a class.
The developer verified that the queries return a single record each and there is error
handling in the Aura component, but the component is not getting anything back when calling the controller getSemeData.
‘What is wrong?
A. Instances of Apex classes, such as MyDatsWrapper, cannot be returned to a Lightning component.
B. The member's Name and option should not have getter and setter.
C. The member's Name and option should not be declared public.
D. The member's Kame and option of the class MyDataWrapper should be annotated with @AuraEnabled also.
Explanation:
Option A: Instances of Apex classes, such as MyDataWrapper, cannot be returned to a Lightning component
This statement is false. Apex classes, including custom wrapper classes like MyDataWrapper, can be returned to a Lightning component (e.g., Aura or LWC) if they are properly annotated with @AuraEnabled. The issue here is not that the wrapper class cannot be returned, but rather that its properties (Name and Option) lack the @AuraEnabled annotation, preventing them from being serialized and accessible to the Aura component. With proper annotation, the wrapper class works fine for data exchange, making this option incorrect.
Option B: The member's Name and Option should not have getter and setter
This statement is false. In Apex, properties within a class (like Name and Option in MyDataWrapper) typically require getters and setters to be accessible and modifiable, especially when used with Aura components. Removing getters and setters would make these properties inaccessible to the component, breaking the data binding. The problem lies in the lack of @AuraEnabled annotation, not the presence of getters and setters, so this option is not the solution.
Option C: The member's Name and Option should not be declared public
This statement is false. Declaring Name and Option as public is necessary for them to be accessible within the class and to the Aura component, assuming they are annotated with @AuraEnabled. Making them private or protected would restrict access, preventing the component from retrieving the data. The issue is the missing @AuraEnabled annotation on these members, not their public visibility, making this option incorrect.
Option D: The member's Name and Option of the class MyDataWrapper should be annotated with @AuraEnabled also
This statement is true and identifies the root cause. The getSomeData method is annotated with @AuraEnabled, allowing it to be called from the Aura component, and it returns an instance of MyDataWrapper. However, the Name and Option properties within MyDataWrapper are not annotated with @AuraEnabled. For the Aura component to access these properties, each must be explicitly marked with @AuraEnabled to enable serialization and deserialization between Apex and the JavaScript controller. Without this annotation, the component receives an empty or null response, explaining why it’s not getting data back despite the queries returning records.
Why Option D?
The issue arises because the Aura component relies on @AuraEnabled to expose Apex properties to the client-side. The method getSomeData is correctly annotated, but its returned MyDataWrapper object’s properties (Name and Option) are not. Adding @AuraEnabled to these members (e.g., @AuraEnabled public String Name { get; set; }) ensures the data is accessible, resolving the problem. The queries returning single records and error handling in the component are irrelevant if the data isn’t properly exposed.
References:
Salesforce Documentation: @AuraEnabled Annotation
Salesforce Platform Developer II Study Guide (covers Aura-enabled methods and properties)
A developer is trying to access org data from within a test class. Which sObject type requires the test class to have the (seeAllData=true) annotation?
A. User
B. RecordType
C. Report
D. Profile
Explanation:
❌ Option A: User
This option is false. The User sObject does not inherently require the @seeAllData=true annotation in a test class. Test classes can create test User records using System.runAs() or other methods within the test context without accessing existing org data. Salesforce allows isolated creation of User records for testing purposes, so this annotation is not mandatory unless the test specifically needs to query existing User records beyond what is created in the test.
❌ Option B: RecordType
This option is false. The RecordType sObject does not require @seeAllData=true by default. Test classes can create test RecordType records or use the Schema class (e.g., Schema.SObjectType.Account.getRecordTypeInfosByName()) to access or create RecordType data within the test context. Existing RecordType records can be queried or referenced without the annotation unless the test depends on specific org-wide RecordType data not created in the test.
✅ Option C: Report
This option is true. The Report sObject requires the @seeAllData=true annotation in a test class because reports are metadata and data combined, and their content (e.g., report definitions, results) is tied to existing org data that cannot be created or manipulated within a standard test context. Without @seeAllData=true, a test class cannot access or query existing Report records, making this annotation necessary to retrieve or validate report data from the org.
❌ Option D: Profile
This option is false. The Profile sObject does not require @seeAllData=true. Test classes can create or reference Profile data using methods like System.runAs() with a test user or by querying existing profiles if needed, but Salesforce allows isolated profile-related testing. The annotation is only required if the test specifically needs to access org-specific Profile records beyond what is created in the test, which is uncommon.
Why Option C?
The Report sObject is unique because it represents a combination of metadata (report definition) and data (report results), which are tied to the org’s existing data and cannot be fully recreated in a test context without accessing live data. The @seeAllData=true annotation allows the test class to see all org data, including Report records, enabling the developer to test report-related logic. This is a known requirement for sObjects like Report, Dashboard, and certain metadata-driven objects, distinguishing it from others like User, RecordType, or Profile.
References:
Salesforce Documentation: Testing with @seeAllData
Universal Containers (LIC) wants to develop a customer community to help their customers log issues with their containers. The community needs to function for their German- and Spanish-speaking customers also. UC heard that it's easy to create an international community using Salesforce, and hired a developer to build out the site. What should the developer use to ensure the site is multilingual?
A. Use custom labels to ensure custom messages are translated properly.
B. Use custom settings to ensure custom messages are translated properly.
C. Use custom objects to translate custom picklist values.
D. Use custom metadata to translate custom picklist values.
Explanation:
✅ Option A: Use custom labels to ensure custom messages are translated properly
This option is true and the best approach for creating a multilingual customer community. Custom labels allow developers to define reusable text values (e.g., button labels, error messages) that can be translated into multiple languages, such as German and Spanish, through Salesforce’s Translation Workbench. When integrated into the community’s Visualforce pages, Lightning components, or Apex code, these labels automatically display the appropriate language based on the user’s language settings. This ensures that custom messages are consistent and properly localized, making it an ideal solution for Universal Containers’ (UC) international community needs, supporting their German- and Spanish-speaking customers effectively.
Option B: Use custom settings to ensure custom messages are translated properly
This option is false for this purpose. Custom settings are used to store configuration data (e.g., key-value pairs) that can be accessed across the org, but they are not designed for translation or multilingual support. While custom settings could store language-specific data, they require manual logic (e.g., Apex code) to switch languages based on user settings, which is less efficient and not a native Salesforce solution for translation. This approach would be overly complex and error-prone compared to using custom labels, making it unsuitable.
Option C: Use custom objects to translate custom picklist values
This option is false. Custom objects can store data, including translations, but they are not a standard or recommended method for translating picklist values or custom messages. Translating picklist values is handled natively in Salesforce through the Translation Workbench, where picklist entries can be translated for each language. Using a custom object would require additional development (e.g., triggers, queries) to map and retrieve translations, adding unnecessary complexity and maintenance overhead, especially for a community site.
Option D: Use custom metadata to translate custom picklist values
This option is false. Custom metadata types are used to define custom configuration data that is deployable and manageable like metadata, but they are not designed for translating picklist values. Like custom objects, this would require custom logic to manage translations, which is redundant since Salesforce provides built-in translation support for picklist values via the Translation Workbench. This approach is overkill and less efficient for the multilingual requirement of the community.
✅ Why Option A?
Custom labels are specifically designed for multilingual applications in Salesforce, including customer communities. They integrate seamlessly with Translation Workbench, allowing UC to translate custom messages into German and Spanish without extensive coding. This native feature ensures the community adapts to users’ language preferences, meeting the requirement to support German- and Spanish-speaking customers. The developer can use these labels in Aura components, Visualforce pages, or Apex, ensuring a consistent and user-friendly experience.
🧩 Additional Context:
The current date and time is 05:00 PM PKT (Pakistan Standard Time) on Tuesday, July 29, 2025, but this does not affect the solution, which is based on Salesforce’s multilingual capabilities.
The developer should also enable Translation Workbench and add the required languages (German, Spanish) to manage translations effectively.
ℹ️ References:
➡️ Salesforce Help: Custom Labels
➡️ Salesforce Developer Guide: Translation Workbench
➡️ Salesforce Platform Developer II Study Guide (covers multilingual support and custom labels)
How should a developer verify that a specific Account record is being tested in a test class for a Visualforce controller?
A. Insert the Account in the test class, instantiate the page reference in the test class, then use System.currentFageReference() .getFarameters() .put{) to set the Account ID.
B. Insert the Account into Salesforce, instantiate the page reference in the test class, then
use system. setFarentRecordId() .get() to set the Account ID.
{of Instantiate the page reference in the test class, insert the Account in
the test class, then use =seeAllData=trus to view the Account.
C. Instantiate the page reference in the test class, insert the Account in the test class, then use system.setFarentRecordrd() .get() to set the Account ID,
Explanation:
✅ Option A: Insert the Account in the test class, instantiate the page reference in the test class, then use System.currentPageReference().getParameters().put() to set the Account ID
This option is true and the correct approach. To test a Visualforce controller with a specific Account record, the developer should first create and insert the Account within the test class to ensure isolated, repeatable test data. Next, instantiate a PageReference to simulate the Visualforce page context, and use System.currentPageReference().getParameters().put() to set the Account ID as a parameter (e.g., Id) that the controller can access. This method mimics how the page would receive the Account ID in a real scenario, allowing the controller to retrieve and process the specific record. It aligns with Salesforce best practices of avoiding @seeAllData=true and ensures the test is self-contained.
❌ Option B: Insert the Account into Salesforce, instantiate the page reference in the test class, then use System.setParentRecordId().get() to set the Account ID
This option is false. There is no System.setParentRecordId() method in Salesforce Apex, making this syntax invalid. Additionally, inserting the Account directly into Salesforce (outside the test class) is not a standard practice for test classes, as it relies on existing org data, which can lead to non-portable and unreliable tests. The correct method involves creating test data within the test class and using System.currentPageReference().getParameters().put() to pass the ID, not a non-existent setParentRecordId() method.
❌ Option C: Instantiate the page reference in the test class, insert the Account in the test class, then use =seeAllData=true to view the Account
This option is false. Using @seeAllData=true allows the test class to access all org data, but it is not necessary or recommended here. The developer can create and insert the Account within the test class without this annotation, ensuring isolated test data. The syntax =seeAllData=true appears to be a typo or misinterpretation; the correct annotation is @seeAllData=true at the class level. Even with this correction, relying on org data defeats the purpose of a controlled test, and no method like setParentRecordId().get() exists to set the Account ID—System.currentPageReference().getParameters().put() is the proper technique.
❌ Option D: Instantiate the page reference in the test class, insert the Account in the test class, then use System.setParentRecordId().get() to set the Account ID
This option is false. Similar to Option B, there is no System.setParentRecordId() method in Apex, rendering this approach invalid. While instantiating the PageReference and inserting the Account in the test class are correct steps, the method to pass the Account ID to the controller should be System.currentPageReference().getParameters().put('Id', accountId). This simulates the page’s parameter passing, allowing the controller to access the specific Account record during the test.
✅ Why Option A?
The correct process involves creating a test Account within the test class to maintain isolation and repeatability, instantiating a PageReference to set up the Visualforce page context, and using System.currentPageReference().getParameters().put() to pass the Account ID. This method ensures the controller can retrieve the specific record (e.g., via ApexPages.currentPage().getParameters().get('Id')) and verifies the test targets that record. It avoids dependencies on org data and adheres to Salesforce testing best practices.
ℹ️ References:
➡️ Salesforce Documentation: Testing Visualforce Controllers
➡️ Salesforce Developer Guide: Test Class Best Practices
➡️ Salesforce Platform Developer II Study Guide (covers testing Visualforce controllers)
Consider the following code snippet:
Which two steps should the developer take to add flexibility to change the endpoint and
credentials without needing to modify code?
(Choose 2 answers)
A. Use req. setindpoint ('callout:endFoint_NC'); within the callout request.
B. Store the URL of the endpoint in a custom Label named endpointuRL.
C. Create a Named Credential, endPcint_wc, ta store the endpoint and credentials.
D. Use red. setEndpoint (Label.endPointURL) ;.
Explanation:
A. Use req.setEndpoint('callout:endPoint_NC'); within the callout request.
This option suggests using a Named Credential (endPoint_NC) to handle the endpoint. Named Credentials in Salesforce allow you to store endpoint URLs and authentication details (like username and password) securely. By using callout: syntax, the endpoint and credentials can be managed in the Named Credential settings, which can be updated without changing the code. This is a best practice for flexibility and security.
B. Store the URL of the endpoint in a custom Label named endpointURL.
Custom Labels allow you to store static values (like URLs) that can be accessed in Apex code using Label.endpointURL. This approach enables the endpoint to be changed via the Salesforce UI (under Custom Labels) without code modification, adding flexibility.
C. Create a Named Credential, endPoint_NC, to store the endpoint and credentials.
This is a valid and recommended approach. Named Credentials can store both the endpoint URL and authentication details (e.g., username and password), which can be updated in the Salesforce setup without altering the Apex code. Using req.setEndpoint('callout:endPoint_NC'); would leverage this configuration.
D. Use req.setEndpoint(Label.endPointURL);
This option builds on option B, where the endpoint URL is stored in a Custom Label (endpointURL). By referencing Label.endPointURL in the code, the developer can update the URL in the Custom Label configuration, avoiding code changes. However, this does not address credentials, which are hardcoded in the original snippet.
Correct Answers:
✅ A. Use req.setEndpoint('callout:endPoint_NC'); within the callout request.
This leverages a Named Credential to manage both the endpoint and credentials dynamically.
✅ C. Create a Named Credential, endPoint_NC, to store the endpoint and credentials.
This sets up the Named Credential that supports option A, providing a secure and flexible way to handle both endpoint and authentication.
Why Not B and D?
❌ B: only addresses the endpoint URL and not the credentials, which are also hardcoded in the snippet (e.g., myUserName and strongPassword). It’s a partial solution.
❌ D: depends on a Custom Label for the endpoint but still requires manual handling of credentials, making it less comprehensive than using Named Credentials.
ℹ️ References:
➡️ Salesforce Documentation on Named Credentials
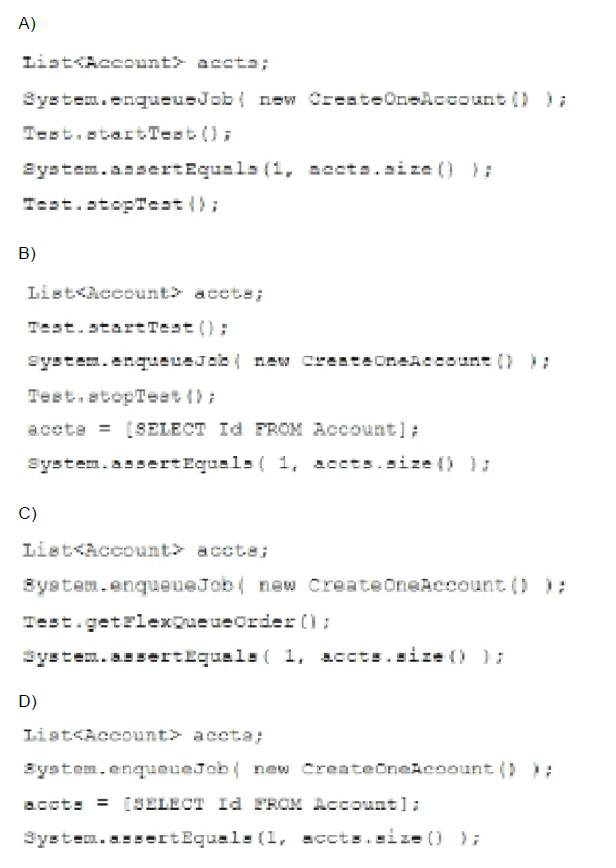
Assuming the CreateOneAccount class creates one account and implements the Queueable interface, which syntax properly tests the Apex code?
A. Option A
B. Option B
C. Option C
D. Option D
✅ Explanation:
🔍 Why Option B is Correct:
Option B correctly uses the Test.startTest() and Test.stopTest() methods to ensure that the CreateOneAccount queueable job actually runs during the test execution. These two methods are essential when testing asynchronous code in Salesforce because they ensure that enqueued jobs are processed. After Test.stopTest(), the code performs a SOQL query to retrieve the inserted account, and then validates the result using System.assertEquals(). This sequence correctly simulates the lifecycle of the queueable job and confirms that the expected account record was created by the job logic.
❌ Why the Other Options Are Incorrect:
❌ Option A — Incorrect
In Option A, the System.enqueueJob() method is called before Test.startTest(), which is acceptable, but the key issue is that the assertion is placed inside the test context and is executed before the asynchronous job runs. Since Test.stopTest() has not yet been called, the job hasn’t had a chance to run and create the account. Additionally, there's no SOQL query retrieving account records before the assertion is made — which means the list accts is never populated and would be null or empty. As a result, the test would either fail or pass incorrectly depending on existing org data, which violates test isolation principles.
❌ Option C — Incorrect
Option C uses System.enqueueJob() correctly to enqueue the queueable class. However, it fails to include the Test.startTest() and Test.stopTest() pair, which are required to execute the asynchronous job during test runs. Instead, it incorrectly uses Test.getFlexQueueOrder() — a method meant for viewing job order in the queue, not for running jobs. Without Test.stopTest(), the job remains in the queue and does not execute, so no account will be created. This causes the assertion to fail or behave unpredictably. Furthermore, like Option A, no SOQL query is performed to retrieve the records before the assertion, making the test logic incomplete and ineffective.
❌ Option D — Incorrect
Option D queues the job and directly performs a SOQL query followed by an assertion. However, it completely omits Test.startTest() and Test.stopTest(), which are required to force the execution of asynchronous jobs during a test. Without these, the job stays in the queue and doesn't run, meaning no account is created at the time of the query. Consequently, the SOQL query will return no records, and the assertion will fail. Even if the job were somehow executed outside the test context (which shouldn’t happen), it would create non-deterministic test results, which are not acceptable in unit testing best practices. The test is therefore unreliable and invalid.
📚 References:
1. Queueable Apex Documentation
Salesforce Developer Guide – Queueable Apex
2. Testing Asynchronous Apex
Salesforce Developer Guide – Test.startTest() and stopTest()
A developer is creating a Lightning web component that displays a list of records in a
lightning-datatable. After saving a new record to the database, the list is not updating.
What should the developer change in the code above for this to
happen?
A. Call rafrasnApex() ON this.dazta.
B. Create a new variable to store the result and annotate it with @track.
C. Create a variable to store the result and call refreshpex().
D. Add the @track decorator to the data variable.
✅ Explanation:
In the code snippet, the developer uses the @wire decorator to call an Apex method (recordList) and retrieve data based on a record ID. The @wire function stores the result in a reactive context, but for that data to be refreshed after a record is created or updated, you must do two things:
➥ Store the result of the wire in a separate variable.
➥ Use refreshApex() and pass it that stored result to re-invoke the Apex method and update the component's data.
🔍 Analysis of Each Option
✅ C. Create a variable to store the result and call refreshApex()
This is the correct approach. refreshApex() is part of the Lightning Data Service and works only if you store the full wire result (not just the data) in a variable. This allows you to manually trigger a refresh of the wired Apex method after an update or create action.
❌ A. Call refreshApex() on this.data
This is incorrect. this.data only stores the response data, not the full wire result. refreshApex() requires the original wire result (which includes metadata about the wire context) in order to re-invoke the method. Calling it on this.data will have no effect.
❌ B. Create a new variable to store the result and annotate it with @track
@track is unnecessary for public class fields in Lightning Web Components (LWC) as they are already reactive by default. Also, simply storing the data with @track does not help in refreshing the wire — only refreshApex() tied to the original wire result will re-invoke the server call.
❌ D. Add the @track decorator to the data variable
This does not solve the problem. In LWC, fields declared at the class level are reactive already, and @track is mostly used for internal mutable objects like arrays or objects — not for managing data re-fetching. Again, the issue is not with reactivity, but with the fact that the wire method needs to be refreshed manually after a data update.
📘 Reference Documentation:
1. Salesforce Developer Guide: refreshApex()
2. Wire Service in LWC
3. Lightning Data Service and Apex in LWC
A company uses Salesforce to sell products to customers. They also have an external
product information management (PIM) system that is the system of record for products.
A developer received these requirements:
* Whenever a product is created or updated in the PIM, a product must be
created or updated as a Product? record in Salesforce and a PricebookEntry
record must be created or updated automatically by Salesforce.
= The PricebookEntry should be created in a Priceboek2 that is specified in a
custom setting.
What should the developer use to satisfy these requirements?
A. Event Monitoring
B. Invocable Action
C. SObject Tree REST
D. Custom Apex REST
✅ Explanation:
This scenario requires Salesforce to receive data from an external system (PIM) and create or update both Product2 and PricebookEntry records. The external PIM is the system of record, meaning it initiates the data exchange. This makes it an inbound integration into Salesforce.
A Custom Apex REST API is the best fit when:
➥ You need to accept incoming HTTP requests from external systems.
➥ You want full control over the logic (e.g., creating/updating records, reading from custom settings).
➥ Complex processing is involved (e.g., lookup of Pricebook2 from a custom setting before creating PricebookEntry).
In this case:
➥ The developer can expose a custom REST endpoint (@RestResource) that the PIM system calls when a product is created or updated.
➥ The Apex method will handle the upsert of the Product2 record.
➥ It will then read the Pricebook2 record (based on the custom setting) and upsert the corresponding PricebookEntry.
❌ Why the Other Options Are Incorrect:
A. Event Monitoring ❌
Event Monitoring tracks user activity (like logins, API usage, and data exports) in Salesforce. It does not allow you to create or update records in Salesforce and is not used for integrating external systems to push data.
B. Invocable Action ❌
Invocable Actions are designed to be called from declarative tools (like Flow or Process Builder), or via Salesforce Outbound messaging. They are not suitable for receiving inbound HTTP requests from external systems like PIM.
C. SObject Tree REST ❌
SObject Tree REST is a standard REST API that allows creation of multiple, related records in a single call — but only when initiated by the external system using Salesforce’s built-in endpoints.
However, this method does not support custom logic (e.g., reading from a custom setting or conditional logic for PricebookEntry). It is limited to straightforward object creation and would require the external system to handle all logic — which is not recommended when business logic needs to be centralized in Salesforce.
📚 Reference Documentation:
Apex REST Services
Custom Settings
SObject Tree REST API
| Page 7 out of 21 Pages |
| 45678910 |
| Salesforce-Platform-Developer-II Practice Test Home |
Our new timed 2026 Salesforce-Platform-Developer-II practice test mirrors the exact format, number of questions, and time limit of the official exam.
The #1 challenge isn't just knowing the material; it's managing the clock. Our new simulation builds your speed and stamina.
You've studied the concepts. You've learned the material. But are you truly prepared for the pressure of the real Salesforce Certified Platform Developer II (SP25) exam?
We've launched a brand-new, timed Salesforce-Platform-Developer-II practice exam that perfectly mirrors the official exam:
✅ Same Number of Questions
✅ Same Time Limit
✅ Same Exam Feel
✅ Unique Exam Every Time
This isn't just another Salesforce-Platform-Developer-II practice questions bank. It's your ultimate preparation engine.
Enroll now and gain the unbeatable advantage of:
Copyright © - All Rights Reserved