Total 234 Questions
Last Updated On : 8-Jul-2026

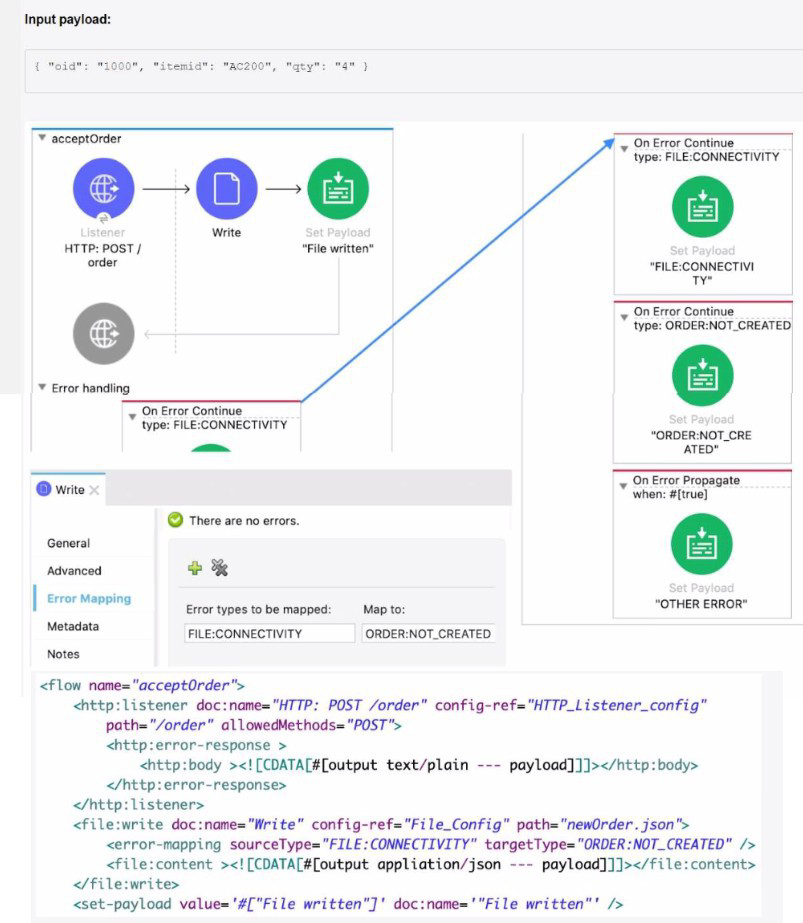
Refer to the exhibits. The Mule application does NOT define any global error handlers.
A web client sends a POST request to the Mule application with this input payload. The File Write operation throws a FILE: CONNECTIVITY error.
What response message is returned to the web client?
A. "FILE: CONNECTMTV
B. "OTHER ERROR"
C. "File written"
D. "ORDER: NOT CREATED"
Explanation:
Error Triggered: The File Write operation throws a FILE:CONNECTIVITY error.
Immediate Error Handler: The Write component is configured with an Error Mapping strategy.
Error Mapping Execution: The Error Mapping within the Write component specifically maps the incoming FILE:CONNECTIVITY error to a new error type: ORDER:NOT_CREATED.
Error Propagation/Handling: Because the Write operation successfully mapped the error, the execution context (the error type) changes from FILE:CONNECTIVITY to ORDER:NOT_CREATED.
Scope/Flow Error Handler Activation: The execution then moves to the acceptOrder flow's Error handling section. It searches for a handler matching the new error type, ORDER:NOT_CREATED.
Handler Selected: The second On Error Continue block is triggered because its type is set to ORDER:NOT_CREATED.
Response Generation: The action inside this On Error Continue block is a Set Payload component, which sets the payload to "ORDER:NOT_CREATED".
Continue Behavior: Since this is an On Error Continue scope, it completes the flow execution successfully (as far as the web client is concerned). The final payload, "ORDER:NOT_CREATED", is returned to the web client.
❌ Incorrect Answers and Reasoning
A. "FILE: CONNECTIVITY": This would be the result if the second On Error Continue was not present, and the first one (for FILE:CONNECTIVITY) was executed, AND that first handler did not use On Error Continue but instead returned the payload. However, the FILE:CONNECTIVITY error is mapped away to ORDER:NOT_CREATED by the Write component before it reaches the top-level error handlers.
B. "OTHER ERROR": This is set in the On Error Propagate block. This block has the generic when: #[#true] condition, meaning it acts as the default catch-all. It would only be reached if the error type was not FILE:CONNECTIVITY or ORDER:NOT_CREATED. Since the error is explicitly handled by the second On Error Continue, the On Error Propagate is never executed.
C. "File written": This payload is set by a component after the Write operation in the main flow. Because the Write operation throws an error, the flow execution is immediately interrupted and moves to the Error Handling block, meaning the subsequent Set Payload "File written" component is skipped entirely.
📚 References
This scenario is based on three core concepts in Mule 4:
Component-Level Error Mapping:
MuleSoft Documentation on Handling Component-Level Errors [Search: MuleSoft documentation error mapping]
Flow-Level Error Handlers (On Error Continue vs. On Error Propagate):
MuleSoft Documentation on Error Handling in Mule 4 [Search: MuleSoft documentation On Error Continue vs On Error Propagate]
Error Scope Behavior (On Error Continue):
When an On Error Continue handler successfully processes an error, it returns a success message to the calling flow or client (the status code defaults to 200 OK), and its payload becomes the response body.
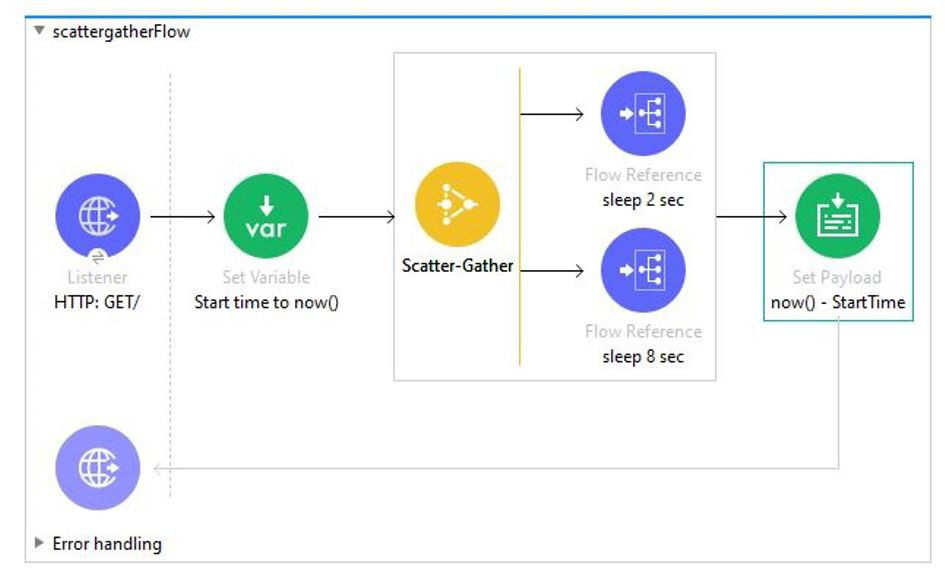
In the execution of scatter gather, the "sleep 2 sec" Flow Reference takes about 2 sec to complete, and the "sleep 8 sec" Flow Reference takes about 8 sec to complete.
About how many sec does it take from the Scatter-Gather is called until the "Set Payload" transformer is called?
A. 8
B. 0
C. 2
D. 10
Explanation:
The key to understanding this question is how the Scatter-Gather router works in Mule 4.
Scatter-Gather Behavior: The Scatter-Gather executes all of its routes concurrently. It does not execute them sequentially. It starts all routes at the same time and then waits for all of them to complete before aggregating the results and moving on to the next processor in the main flow.
Execution Timeline:
Time = 0 sec: The Scatter-Gather starts. It immediately launches both the "sleep 2 sec" and "sleep 8 sec" routes at the same time.
Time = 2 sec: The "sleep 2 sec" route finishes its execution. The Scatter-Gather has one result but continues to wait for the other route.
Time = 8 sec: The "sleep 8 sec" route finishes its execution. Now that all routes are complete, the Scatter-Gather aggregates the results (if any) and proceeds.
Total Time: Therefore, the total time from when the Scatter-Gather is called until it finishes and the subsequent Set Payload processor is called is determined by the longest-running route. In this case, that is 8 seconds.
Why the others are incorrect:
B. 0: This is incorrect because both routes perform a sleep operation, which takes real time. The Scatter-Gather does not bypass or ignore the processing time of its routes.
C. 2: This is the duration of the fastest route, but the Scatter-Gather must wait for the slowest one.
D. 10: This would be the result if the routes ran sequentially (2 + 8), but the Scatter-Gather's primary feature is parallel execution.
Reference:
MuleSoft Documentation - Scatter-Gather Router. The documentation states: "The Scatter-Gather component executes a set of routes in parallel, then aggregates the results into a single message." Its execution time is bound by the slowest parallel route. This concept falls under the Controlling Message Flow (19%) domain of the exam guide.
How are multiple conditions used in a Choice router to route events?
A. To route the same event to the matched route of EVERY true condition
B. To find the FIRST true condition, then distribute the event to the ONE matched route.
C. None of these
D. To find the FIRST true condition, then route the same event to the matched route and ALL FOLLOWING routes
✔️ Explanation:
The Choice Router in Mule works like an IF–ELSE IF–ELSE chain:
Mule evaluates each condition in order (top to bottom).
As soon as it finds the first condition that evaluates to true,
→ the event is routed to that ONE route only.
No other conditions are evaluated after the first match.
If none match, Mule uses the default route (if present).
❗ Important:
The event is not sent to multiple routes.
The event does not continue evaluating conditions after the first true one.
❌ Why the other options are wrong
A. To route the same event to EVERY true condition
Incorrect — Choice Router is not a Scatter-Gather. It picks only one route.
D. To route to the matched route and ALL following routes
Incorrect — it routes to one route only.
C. None of these
Incorrect — because option B is correct.
A flow needs to combine and return data from two different data sources. It contains a Database SELECT operation followed by an HTTP Request operation.
What is the method to capture both payloads so the payload from the second request does not overwrite that from the first?
A. Put the Database SELECT operation inside a Cache scope
B. Put the Database SELECT operation inside a Message Enricher scope
C. Nothing, previous payloads are combined into the next payload
D. Save the payload from the Database SELECT operation to a variable
Explanation:
In MuleSoft, each operation updates the payload with its result. That means:
The Database SELECT operation sets the payload to the query result.
The HTTP Request operation then overwrites the payload with its response.
If you need to combine data from both sources, you must preserve the first payload before it gets overwritten. The standard way to do this is to store the Database SELECT result in a variable (e.g., dbResult) using the Set Variable component. Later, you can reference this variable and merge it with the HTTP response payload.
❌ Why the Other Options Are Incorrect:
A. Cache scope ❌ Used for caching results to improve performance, not for preserving payloads between operations.
B. Message Enricher scope ❌ Message Enricher is used to enrich the message with additional data from a nested operation, but in this case, you want to explicitly capture both payloads. While Message Enricher could technically help, the exam expects the simpler and more direct solution: saving the first payload to a variable.
C. Nothing, previous payloads are combined ❌ Incorrect — Mule does not automatically combine payloads. Each operation replaces the payload with its own result.
🔗 Reference:
MuleSoft Docs – Variables
MuleSoft Docs – Message Structure
Refer to the exhibit.
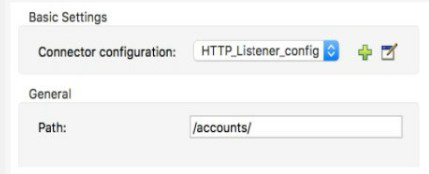 What is the correct syntax to add a customer ID as a URI parameter in an HTTP Listener's path attribute?
What is the correct syntax to add a customer ID as a URI parameter in an HTTP Listener's path attribute?
A. (customerlD)
B. {customerlD}
C. #[customerlD]
D. ${ customerID}
Explanation:
URI Parameter Syntax: When defining an HTTP Listener's path in Mule 4, URI parameters (also known as path parameters) are defined using curly braces ({}) around the parameter name.
Example: If the Listener path is set to /accounts/{customerID}, a request to /accounts/12345 will be accepted.
Accessing the Parameter: The value of the URI parameter (12345 in the example) is then automatically extracted and made available in the Mule event as an attribute under attributes.uriParams.customerID.
❌ Incorrect Answers and Reasoning
A. (customerID): Parentheses are not the correct syntax for defining URI parameters in a Mule HTTP Listener path. This syntax is not used for this purpose in Mule.
C. #[customerID]: The #[...] syntax is used for DataWeave expressions to dynamically access variables, payloads, or attributes during message processing (runtime). It is not the correct way to define a path parameter in the Listener's configuration.
D. ${customerID}: The ${...} syntax is used for Mule Configuration Properties (placeholders) that are resolved when the application starts up. This is used for defining environment-specific values (like ports or credentials) from a properties file, not for defining variable parts of a request URI.
📚 References
MuleSoft Documentation on HTTP Listener: "The path parameter is defined by enclosing its name in curly braces (e.g., /users/{id}) in the Listener's path configuration."
MuleSoft Documentation on URI Parameters: "URI parameters are accessible in a flow using the DataWeave expression attributes.uriParams."
Refer to the exhibits.
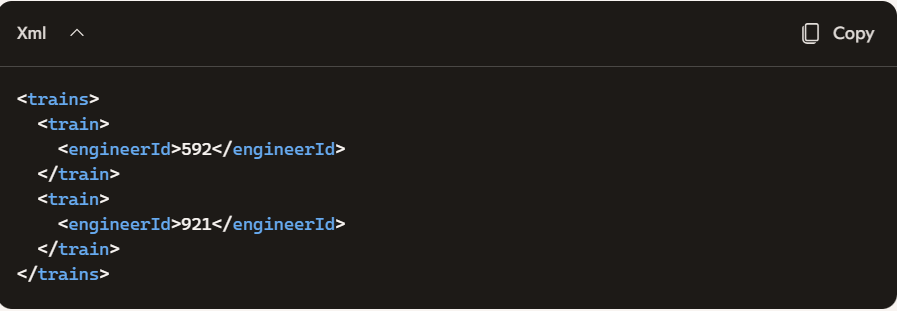
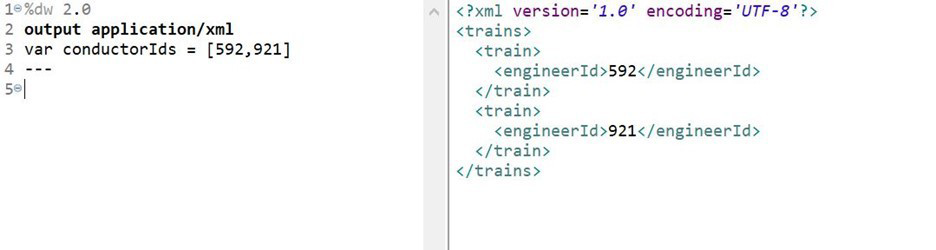 What DataWeave expression transforms the conductorIds array to the XML output?
What DataWeave expression transforms the conductorIds array to the XML output?
A. 1. 1. trains:
2. 2. conductorIds map ((engId, index) ->
3. 3. train: {
4. 4. engineerId: engId
5. 5. }
6. 6. )
B. 1. 1. { trains:
2. 2.
3. 3. conductorIds map ((engId, index) ->
4. 4. train: {
5. 5. engineerId: engId
6. 6. }
7. 7. )
8. 8. }
C. 1. 1. trains:
2. 2. {(
3. 3. conductorIds map ((engId, index) ->
4. 4. train: {
5. 5. engineerId: engId
6. 6. }
7. 7. )
8. 8. )}
D. 1. 1. {( trains:
2. 2.
3. 3. conductorIds map ((engId, index) ->
4. 4. train: {
5. 5. engineerId: engId
6. 6. }
7. 7. )
8. 8. )}
Explanation:
This DataWeave expression correctly transforms the array conductorIds = [592, 921] into the desired XML structure:
 Let’s break it down:
Let’s break it down:
trains: defines the root element.
{(...)}: wraps the result of the map operation inside the trains object.
conductorIds map (...): iterates over each ID.
train: { engineerId: engId } creates a train element with a nested engineerid.
The parentheses around the map block ({(...)}) are crucial — they ensure the mapped array is unwrapped into individual train elements inside trains.
❌ Why the Other Options Are Incorrect:
A. Missing outer braces {(...)}: — would cause a syntax error or incorrect structure.
B. Wraps everything in { trains: ... } but lacks the unwrapping parentheses: — results in a nested array inside trains, not individual
D. Starts with {( trains: ... )}: — invalid syntax; the placement of {( is incorrect.
🔗 Reference:
MuleSoft Docs – DataWeave XML Output
DataWeave Language Guide – Mapping and Object Construction
Refer to the exhibit.
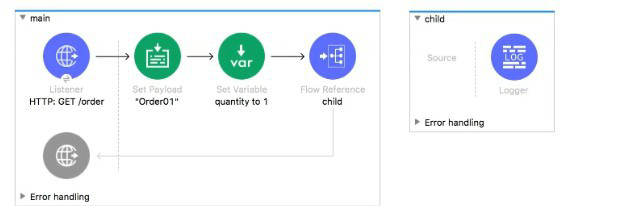
The main flow contains a Flow Reference for the child flow.
What values are accessible in the child flow after a web client submits a request to http://localhost:8Q81/order? color=red?
A. payload
B. payload quantity var
C. payload color query param
D. payload quantity var color query param
Explanation:
When a Flow Reference component is used to call another flow, the entire Mule event (including its current state) is passed from the parent flow to the child flow. The child flow operates on the same event instance, unless an error occurs or the event is explicitly altered.
Let’s trace what is available in the child flow when it is called from the main flow:
Initial Request: The web client sends GET /order?color=red.
HTTP Listener (main flow): This component creates the initial event.
payload: The payload is set to the body of the HTTP request. For a GET request with no body, this is typically an empty string or null, but the payload variable exists and is accessible.
attributes: The HTTP request attributes (headers, query params, etc.) are stored here. Specifically, the query parameter color=red is accessible via attributes.queryParams.color or simply attributes.queryParams['color'].
Set Variable (main flow): The processor
vars.quantity: This variable (quantity) is now part of the event and is set to 1.
Flow Reference (main flow): The child flow is invoked. At the moment of invocation, the event contains:
- The current payload.
- The current attributes (including the color query param).
- The current variables (including quantity).
All of these components (payload, vars.quantity, attributes.queryParams.color) are accessible in the child flow because they are part of the same event context passed by reference.
Why the others are incorrect:
A. payload: This is true but incomplete. The child flow has access to much more than just the payload.
B. payload quantity var: This is also incomplete. It misses the HTTP query parameters, which are a key part of the request and stored in attributes.
C. payload color query param: This is incomplete. It misses the quantity variable that was explicitly set in the main flow before the Flow Reference.
Reference:
MuleSoft Documentation - Flow Reference Component and Mule Event Structure. The documentation states that flows called via Flow Reference share the same Mule event, meaning all its parts (payload, attributes, variables, error) are accessible. This tests knowledge from the Controlling Message Flow (19%) and Handling Errors (22%) domains, specifically regarding event propagation between flows.
Refer to the exhibit.
A. Option A
B. Option B
C. Option C
D. Option D
Explanation:
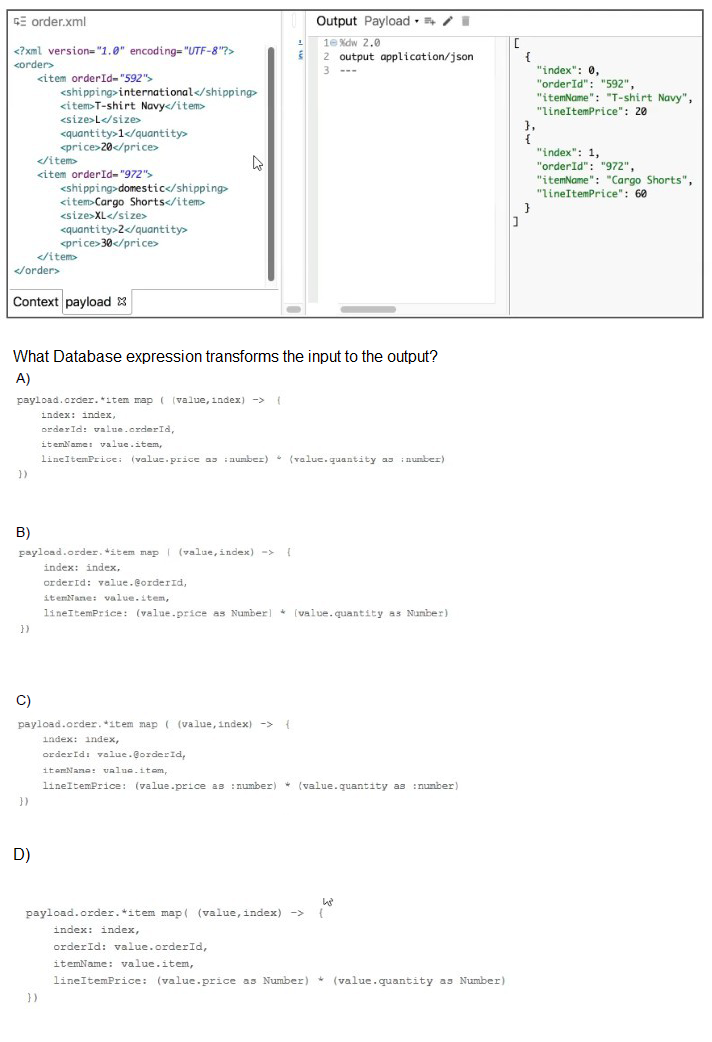
Iterating Over Items: The goal is to create one JSON object for every item element inside the order element in the XML. The correct path to access these repeated elements is payload.order.*item. The * is necessary to access the multiple item nodes in the XML structure.
Mapping Function: The map function correctly iterates over the list of items, assigning the current item's data to the variable value and its index to the variable index.
Output Structure: Inside the map, an object {...} is created for the JSON output.
Index: index (the second parameter in the map function) provides the zero-based index of the current item, fulfilling Index: index.
orderId: The orderId attribute of the
itemName: The content of the deeply nested item tag within item is accessed as value.item.
lineItemPrice: The calculation (value.price as :number) * (value.quantity as :number) correctly accesses the text content of the price and quantity children of the current item node, casts them to numbers for multiplication, and provides the required field.
❌ Incorrect Answers and Reasoning
A. Option A: This option uses payload.order.item instead of payload.order.*item. In DataWeave, accessing an XML node that is expected to be an array of multiple elements (like
B. Option B: This option has two key errors:
- It uses the wrong path: payload.order.*item is missing the s in *items. The XML shows the node name is item.
- It incorrectly casts to Number (uppercase). DataWeave 2.0 type coercion uses lowercase :number (or just number).
D. Option D: This option has the same incorrect casting as Option B, using Number instead of :number.
📚 References
DataWeave Documentation on XML Iteration: Using the selector .* is the standard way to select and iterate over repeated elements in an XML structure when they are not the root of the document.
DataWeave Documentation on Type Coercion: Explicit type casting for arithmetic operations requires the use of the :type notation (e.g., :number or as number). The uppercase Number is typically an incorrect syntax.
Refer to the exhibits.

The Set Payload transformer's value is set to {'year': '2020'}.
What message value should be added to the Logger component to output the message 'The year is 2020', without hardcoding 2020?
A. '#[The year is $(pay load .year)]*
B. The year is #[payload.year]'
C. '#[The year is " + paytoad.year]'
D. #["The year is "++ payload.year].
Explanation:
The payload is:
{ "year": "2020" }
To log:
The year is 2020
• Without hardcoding 2020
• Using valid DataWeave expression syntax inside the Logger
You need:
✔ String concatenation
DataWeave uses ++ for concatenation:
"The year is " ++ payload.year
Wrapped in an expression:
#["The year is " ++ payload.year]
This matches Option D.
❌ Why the other options are incorrect
A. '#[The year is $(payload.year)]'
${} syntax is for property placeholders, not DW.
Wrong DW syntax.
B. 'The year is #[payload.year]'
Mixing literal text + DW expression is invalid without proper formatting.
DW inside quotes is not evaluated.
C. '#[The year is " + payload.year]'
Uses Java-style string concatenation (+) which is invalid in DW.
Missing quotes around the literal string.
Which out of below is not an asset?
A. Template
B. Connector
C. Exchange
D. Example
Explanation:
In the context of Anypoint Platform and MuleSoft's terminology, an asset is a reusable component or piece of content that can be developed, shared, and deployed. The Anypoint Exchange is the central repository where these assets are stored, discovered, and managed.
Let’s break down each option:
A. Template: Is an asset. Templates are pre-built project skeletons (e.g., API-led connectivity templates, Salesforce integration templates) available in Exchange to accelerate development.
B. Connector: Is an asset. Connectors (like Salesforce, Database, HTTP) are modular components published to Exchange that provide connectivity to external systems. They are installed as dependencies in a Mule project.
C. Exchange: Is NOT an asset. Anypoint Exchange is the platform service or portal itself—the marketplace or repository where assets (like Templates, Connectors, Examples, RAML specs, and Policies) are stored and shared. It is the container, not the content.
D. Example: Is an asset. Examples are specific, illustrative instances of code, configurations, or projects shared on Exchange to demonstrate how to use an API, connector, or other asset.
Therefore, Exchange is the service that hosts the assets, making it the item that is not classified as an asset itself.
Reference:
MuleSoft Documentation - Anypoint Exchange. The documentation describes Exchange as "a built-in, central repository for discovering, sharing, and reusing assets," clearly differentiating the repository from the assets it contains. This concept is part of the foundational knowledge for the Understanding MuleSoft (10%) domain.
| Page 7 out of 24 Pages |
| 345678910 |
| Salesforce-MuleSoft-Developer Practice Test Home |
Our new timed 2026 Salesforce-MuleSoft-Developer practice test mirrors the exact format, number of questions, and time limit of the official exam.
The #1 challenge isn't just knowing the material; it's managing the clock. Our new simulation builds your speed and stamina.
You've studied the concepts. You've learned the material. But are you truly prepared for the pressure of the real Salesforce Certified MuleSoft Developer - Mule-Dev-201 exam?
We've launched a brand-new, timed Salesforce-MuleSoft-Developer practice exam that perfectly mirrors the official exam:
✅ Same Number of Questions
✅ Same Time Limit
✅ Same Exam Feel
✅ Unique Exam Every Time
This isn't just another Salesforce-MuleSoft-Developer practice questions bank. It's your ultimate preparation engine.
Enroll now and gain the unbeatable advantage of:
Copyright © - All Rights Reserved